多元智能与人工智能 孩子的语言智能

不断培养孩子的语言智能,大力开发人工智能设备语言智能技术。人工智能技术的发展不仅需要电子硬件、软件算法等专业的毕业生,更需要语言学专业的毕业生。语言智能发达的孩子,不仅能胜任众多工作,还将在人工智能设备发展和应用中大展身手。
学习人工智能技术就好似射击移动靶,并且靶在加速。
不断培养孩子的语言智能,大力开发人工智能设备语言智能技术。人工智能技术的发展不仅需要电子硬件、软件算法等专业的毕业生,更需要语言学专业的毕业生。语言智能发达的孩子,不仅能胜任众多工作,还将在人工智能设备发展和应用中大展身手。

无论是我们的孩子,还是我们设计开发的人工智能设备,他们/她们/它们都是我们的后代,当他们/她们/它们最大限度的发挥这些多元智能,我们的未来将无与伦比。
Camellia 2019年9月26日
人工智能设备的语言智能技术涉及语言学理论、人工智能等多项知识和技术,横跨多学科、多领域等内容,尤当今理论研究进展勇猛、技术发展迅速,Camellia Café 在文中仅抛砖引玉,简述基本概念、略举范例、并大胆展望。
计算语言学 Computational Linguistics
+ 发展语言学 Development
+ 结构语言学 Structure
+ 产生语言学 Production
+ 理解语言学 Comprehension
机器学习与深度学习 Machine Learning and Deep Learning
+ 机器学习 Machine Learning
+ 人工神经元网络 Artificial Neural Networks
自然语言处理技术 Natural Language Processing
+ 人类语言学知识 Linguistics
+ 自然语言处理的任务 Functions
+ 自然语言处理的方法 Steps
+ 单词模型 Word2Vec
+ 句子模型 Parse
+ 递归神经元网络 Recurrent Neural Networks
+ 卷积神经元网络 Convolutional Neural Networks
语言智能的硬件技术 Hardware
强人工智能 Instinct Intelligence

我们梦想着、并努力着,使我们周围的自动导航汽车、智能家电、机器人等人工智能设备可以更加准确地听懂我们的话语,更加流畅地和我们交流,它们可以讲述多国语言,可以抑扬顿挫地演讲、可以一语双关,可以理解字里行间的隐喻和感情,可以写诗撰稿,并最终和我们生活在一起。但是机器就是机器,它们暂时没有我们人类般的大脑,不具备真正的学习、思考等能力,目前本质还是处理0和1这两个数字,虽然量子技术的发展将会从基本概念上带来根本的改变,但是当前让人工智能设备具备人类语言智能,本质是使其具有计算语言功能,从技术角度的出发,就是软件算法的设计。
计算语言试图找出自然语言( Natural Language )的规律,建立运算模型,让人工智能设备能够像人类般分析、理解和处理自然语言。
计算语言功能的研究主要包括:
Developmental Linguistics 语言的发展
人类语言的发展实际是一个不断地学习过程,无论是喃喃学话的孩子,还是我们学习外语,研读古籍,我们都在吸收新的内容。而网络和社交媒体技术的发展,使得每年都有许多网络新词( cyber neologism )被收编到权威字典中。人工智能设备不仅需要自身掌握学习语言的能力,不断地学习人类语言,待到人工智能高度发展的未来,其同样可以帮我们预测和指导人类语言的发展。

为了模拟人类学习语言的过程,就需要在人工智能设备内部建立相关的模型,通常采用统计语法( Statistical Grammar )学和关联模型( Connectionist Model )等方法。
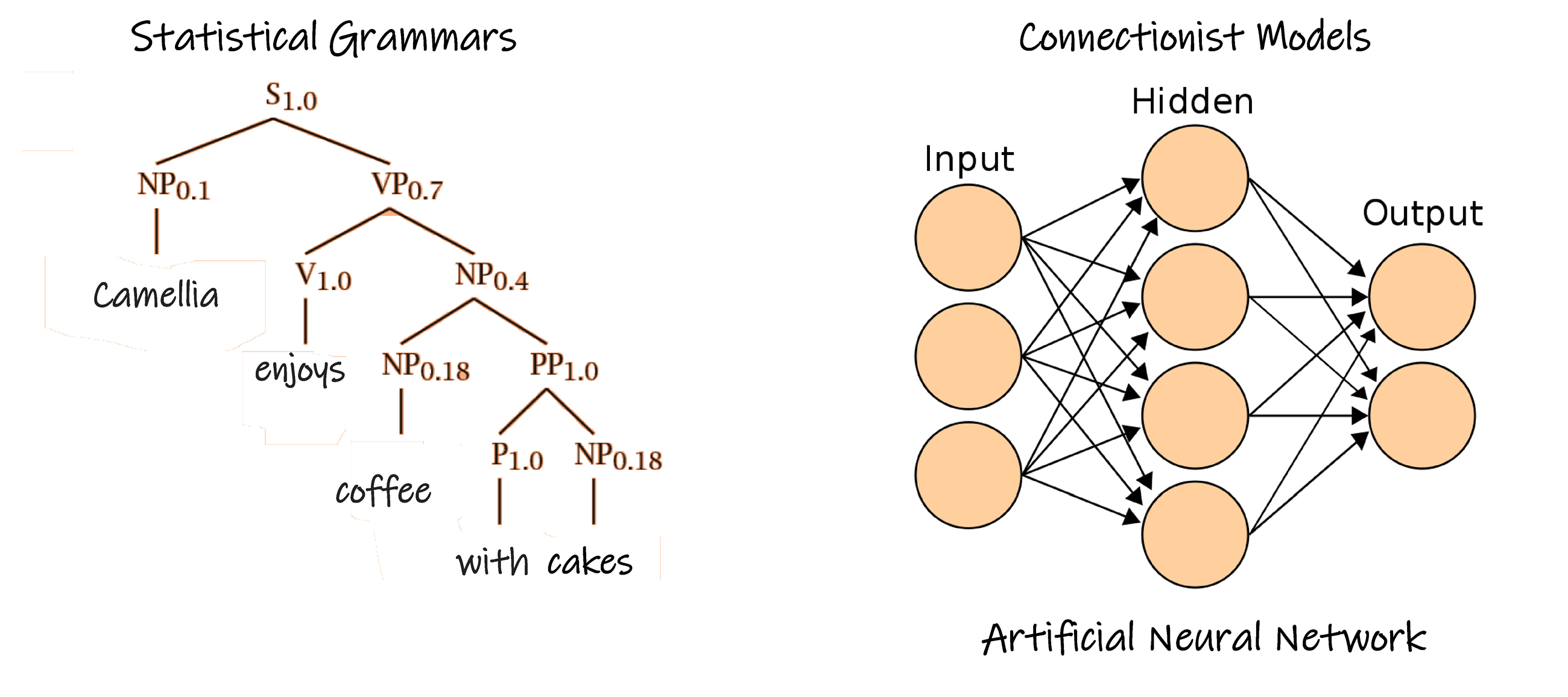
人工智能设备在学习语言时,由于语法等原因,长语句、长文章的机器分析,会生成多种分析结果,产生歧义,人工智能技术需要解决这种困难,采用统计( statistical )、概率( probabilistic )、甚至时间概率( stochastic )等方法加以纠正,消除歧义。统计语法学是一种建立在符合语法概率基础上的语法框架,其概率模型通常由非概率模型和数字量构成,与非概率模型相比,概率模型并不简单,结构也没有简化。这种统计方法也需要基于机器学习和数据挖掘等数据分析技术。
关联模型是把已经获得的语言数据和已有的分析结果建立映射关系,人工神经元网络模型是一种常见的方法。
Structural Linguistics 语言的结构
为了建立最佳的语言计算模型,必须深入了解语言的结构。而研究语言结构的重要环节就是获取大量的语言资料库信息,即样本。这些样本使得建立模型成为可能,并且对某种语言的关键结构的理解产生了重要的作用。
样本获得后,首先需要分析处理,使人工智能设备理解语言结构。分析处理的方法包括注释( annotation )、信息提取( abstraction )和分析( analysis )等。
+ 注释:包括结构审定( structural markup )、词性标记( part-of-speech tagging )、语法分析( parsing )等。
+ 信息提取:通过样本,在理论模型中建立各变量之间的对应关系。
+ 分析:包括直接研究,统计搜索,统计评估,规则优化和知识发掘等。
Treebank 是一种常用的用于句子语义和句法标注的语言结构模型。其中语义( semantic )标注顾名思义就是标注句子的含义,当句子的含义较多时,Treebank 需要较深的深度。而句法( syntactic )标注,则需要同时考虑句子的结构顺序和语义。
语言结构模型的建立目前需要大量的语言学理论知识。
Linguistic Production and Comprehension 语言的产生和理解
把这两块内容结合在一起介绍,是基于人工智能设备产生语言的过程同人类一样,即把想法转换为问题,但更重要的是:保证其产生的语言包含有用的信息,并且无论写还是说,都需要具备技巧,使语言流利。因此语言产生离不开语言的理解,当前人工智能设备的语言产生技术首先要基于互动系统,包括文字识别和语言识别。文字识别就是提取书籍、图像、网页等中的文字。语言识别就是识别声音和音乐,并把声波转换为文字。例如 iOS 中的 Siri ,因此,声音识别技术也是计算语言的一个重要研究方面。
为了达到上述效果,需要对模型输入大量的人类语言进行训练,并同时分析人类的性格,例如经验开放性( Openness to experience)、尽责性( Conscientiousness )、外向性( Extraversion)、亲和性( Agreeableness )、情绪不稳定性( Neuroticism)等。在整个过程中,人工智能设备内部的模型通过参数分析对大量的语言风格进行分类,使得人机交流更加自然流畅。

为了交流互动,产生语言,人工智能设备需要会听、善读,当前人工智能设备主要采用自然语言处理技术,更好地理解人类的想法。
上述四个方面中,人工智能设备的语言的发展学习、语言的产生和语言的理解都需要机器学习技术,机器学习技术是人工智能技术的一个重要组成部分。
当前的机器学习技术包括以下四种方式:
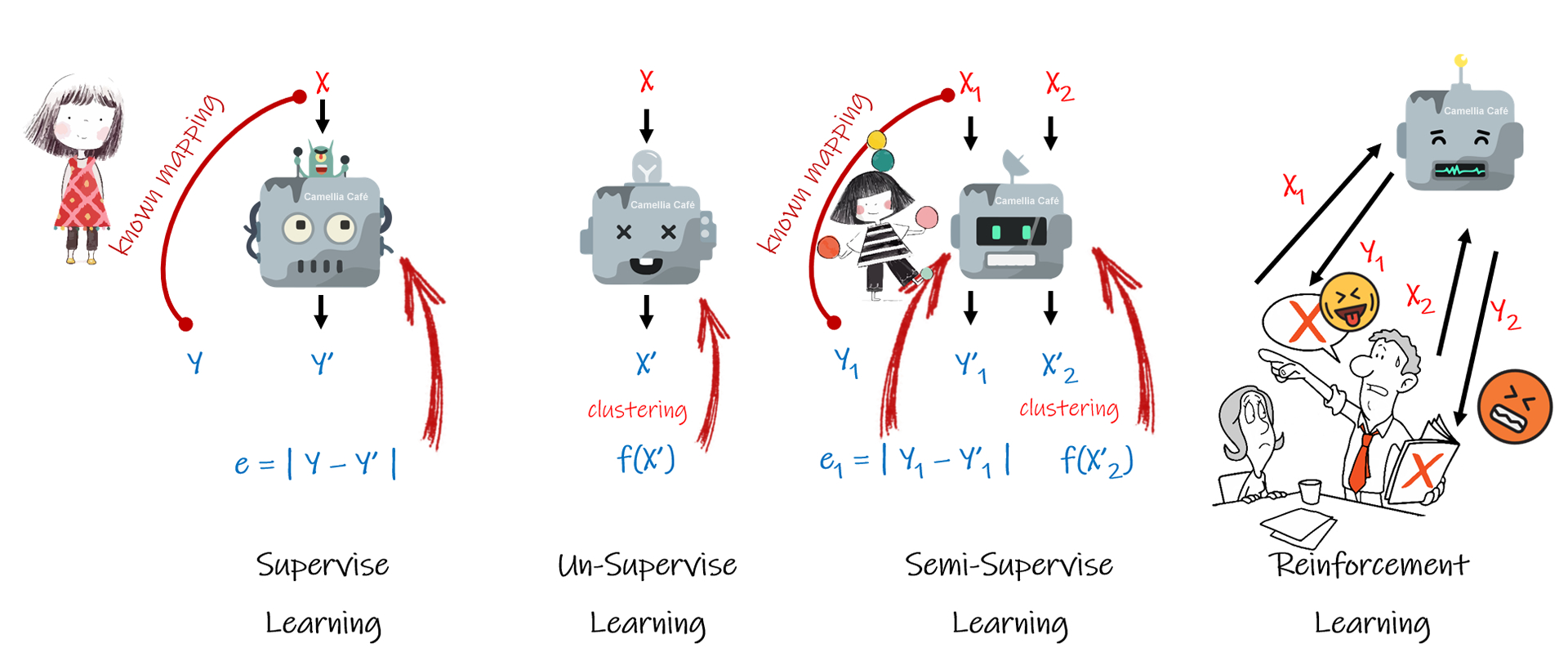
监督学习 Supervise
人工智能设备也需要老师,人工智能设备学习时,人类给与监督和指导。对人工智能设备内部的模型,输入一组信息,并且已经掌握了该组输入信息对应的正确输出信息,通过模型的自身计算,得出一组模型的输出,把模型的输出与正确的输出进行比较,并根据偏差调整模型参数,继续让模型反复学习,直到偏差小于一定值时,初步认为学习完成。注意这只是学习的初步完成,并不意味着模型的建立成功,在下文中将揭示其原因。
非监督学习 Un-supervise
顾名思义,非监督的学习方式就是人工智能设备在没有人类监督和指导的前提下,自己学习,把一组输入信息映射( mapping )或聚类( clustering )到一组输出信息,即产生一组新的信息,通过对新的信息进行某种指标评价,当指标评价值不高时,则调整模型参数,重新映射或聚类,直到评价指标值满足一定的期望。
半监督学习 Semi-Supervise
半监督学习是基于上述两种模式的综合,即模型的某部分输出需要与标准输出进行比较,某部分输出需要采用指标评价值考评映射或聚类后的信息。
增强学习 Reinforcement Learning
增强学习是把人工智能设备放到一定的环境中,通过人工智能设备主动获取周围环境的信息,作为其输入,并产生一定的输出,该输出作用到周围环境中,把周围环境等的反馈作为一种评价指标,来考评人工智能设备内部模型的性能,并根据该评价指标来调整模型的参数。当人工智能设备多次获得高指标值后,证明人工智能设备已经完成了学习,很好地适应了周围的环境。
机器学习的重要应用就是使人工智能设备自行建立模型。通常建立模型的方法如下图,基于规则的建模和机器自学习建模是两大方法。其中机器学习又分为普通机器学习和表征(特征)学习( Representation Learning ),下文将要讲述的深度学习( Deep Learning )又是表征(特征)学习中的特例。表征(特征)学习相对于普通机器学习,从输入信息中提取了更多的特征值。而深度学习的进步之处在于,在已提取的特征值的基础上,进一步抽象和归纳,可以处理更加复杂的任务。
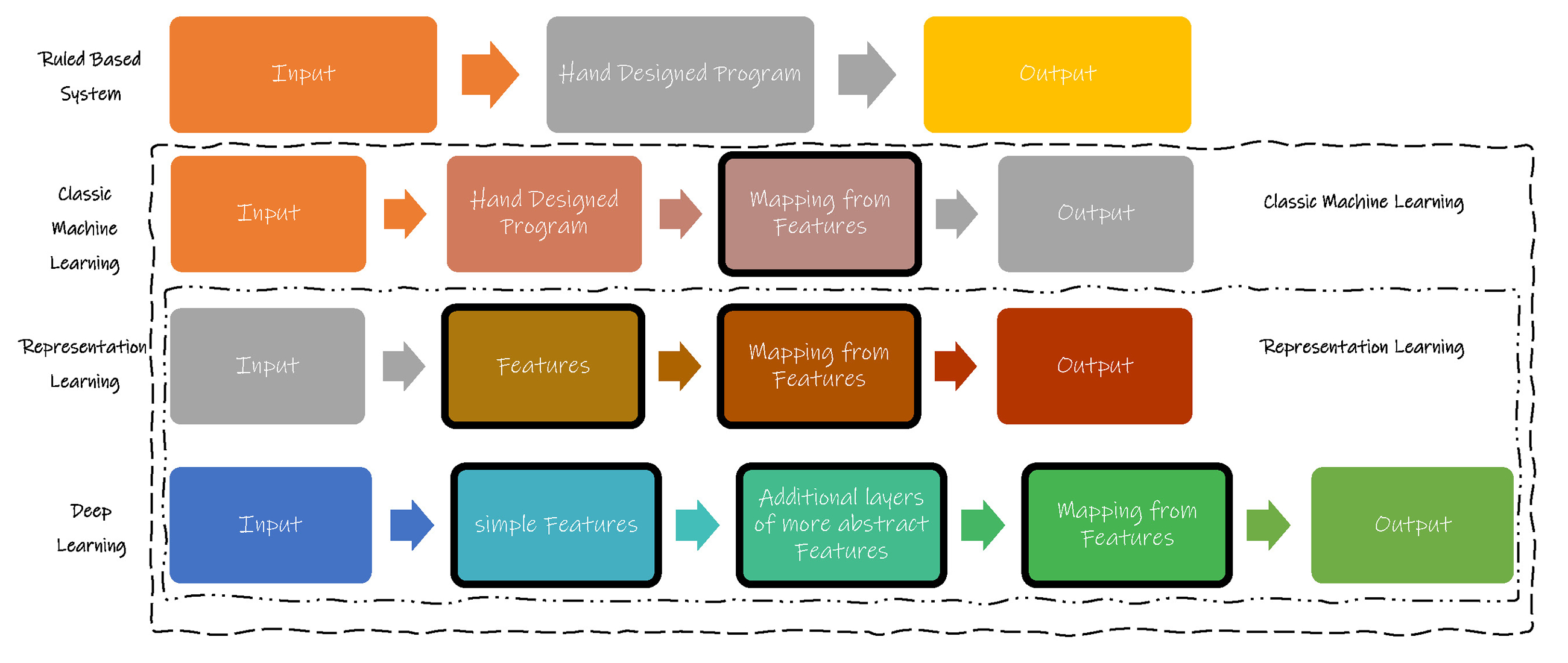
深度学习就是基于复杂人工神经元网络模型的表征式的机器学习,并且具备终生学习的功能。
人工神经元网络 Artificial Neural Networks
人工神经元网络技术模仿人类的神经元细胞,每个人工神经元细胞都有多个突触,每个神经元细胞通过某个突触与其他神经元细胞连接到一起。每个神经元接受其他神经元传递来的信息,在其细胞内进行一定的处理,并把处理结果传递到其他神经元细胞,多个神经元细胞通过连接形成了大脑网络。
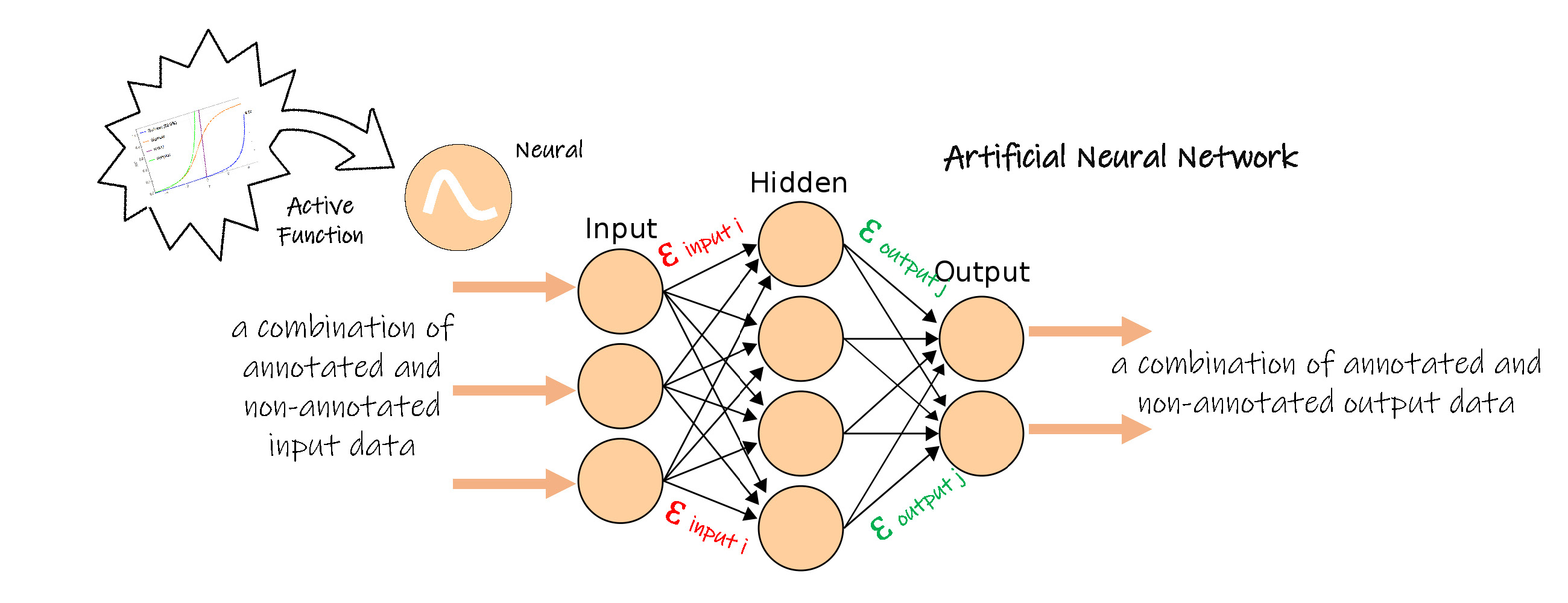
人工神经元网络模型由多个节点构成,每个节点都是一个计算函数,其中一组节点接收外部输入信息,这称作输入层节点,每个输入节点对输入信息进行简单或复杂的运算,向下一组节点传递,在传递的过程,需要把运算后的信息乘上该路径的系数后,才能作为下一组节点的输入,这个系数就称作权值。下一组中的每个节点接收多个输入节点传递来的信息,再次进行简单或复杂的运算,这组节点称作隐藏层节点。通常可以有一组或多组隐藏层节点,即某个隐藏层输出,再次乘以路径上的权值后,传递到下一组隐藏层。最后一组隐藏层乘以权值后输出到另一组节点,即输出层节点,每个输出层节点汇总前一隐藏层节点的信息,作为人工神经元网络的最终输出。
人工神经元网络模型的建立就是其学习的过程,人工神经元网络可以具备上述四种学习方式。
这里以监督学习为例,简要介绍学习即建立模型的过程。
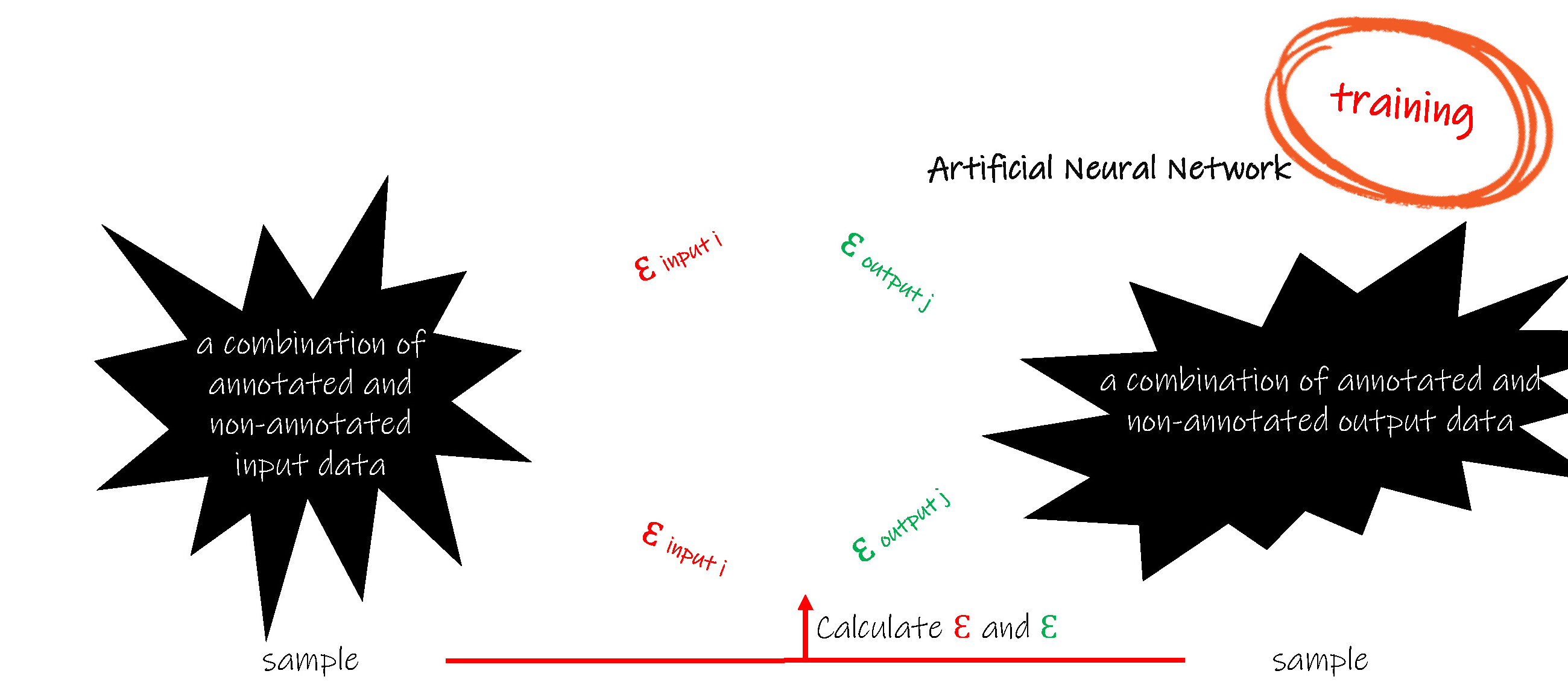
通常采用一组已知的输入数据和其对应的输出数据(标准输出)作为人工神经元网络的训练( training )样本,把输入数据加载在人工神经元网络模型的输入层上,让数据从输入层到隐藏层再到输出层进行正向计算( forward calculation ),得出模型的输出数据,把模型的输出数据与已知的标准输出数据进行比较,并把偏差反向传播( back propagation ),在反向传播的过程中,根据一定的算法(例如最小二乘法、主元回归分析等)更新网络中的每个权值。反向传播后,采用另一组新的输入数据和标准输出数据重新开始新一次的训练,直到偏差趋向于零。训练过程,由于训练的样本有限以及训练样本的非多样化,应当避免偏差的局部最小,追求偏差的全局最小。
训练开始前还需要对所有权值进行初始化,才能保证第一次的正向计算可以进行。权值的初始化也是一个研究问题,与训练样本的特性一样,其同样需要保证多样性。

接着应采用多组新的数据,再次进行前向计算,这些数据必须独立于上述所有训练数据,这个过程称作泛化( generalising and checking )。当泛化的结果,即该过程的偏差足够小时,才能认为模型学习的基本成功。
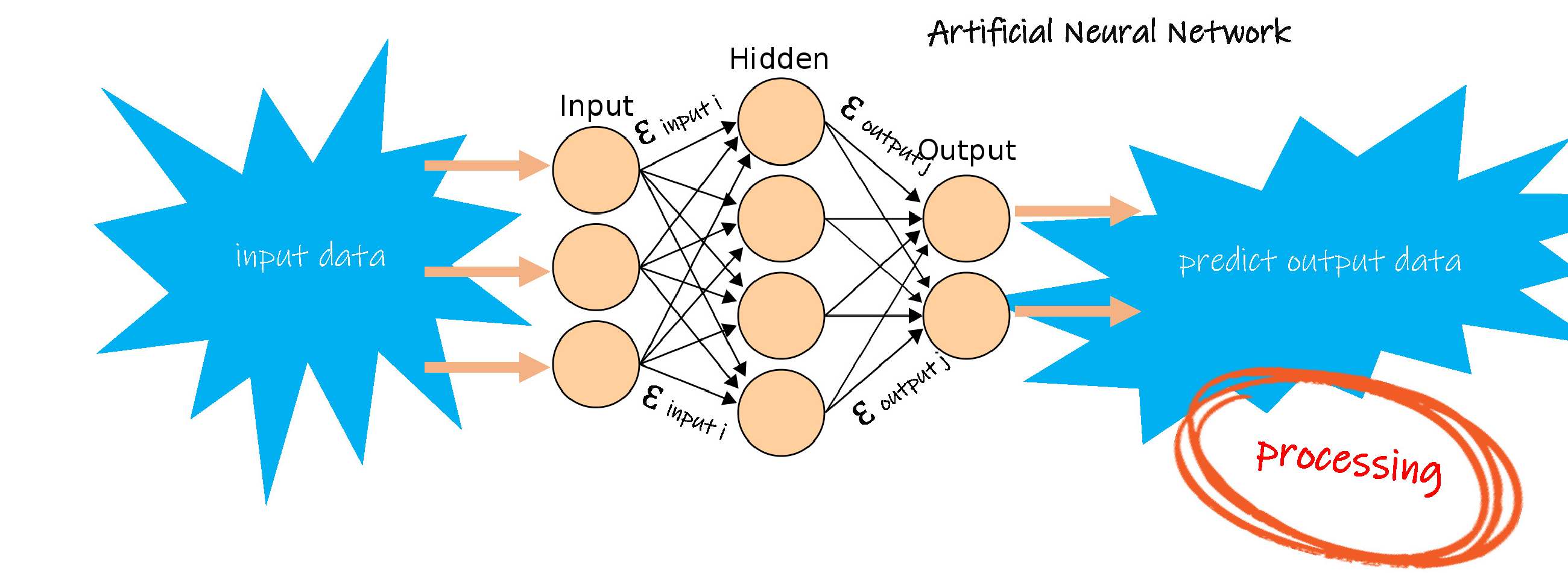

泛化就好似考试,学生完成了学业,考试成绩合格,才可以走出校门,走上工作岗位。同样,训练和泛化完成后的人工神经元网络模型,正式投入使用。此时采用一组未知对应输出信息的输入数据,作为模型的输入,单凭模型的自身计算,其结果就是人工智能设备的输出。
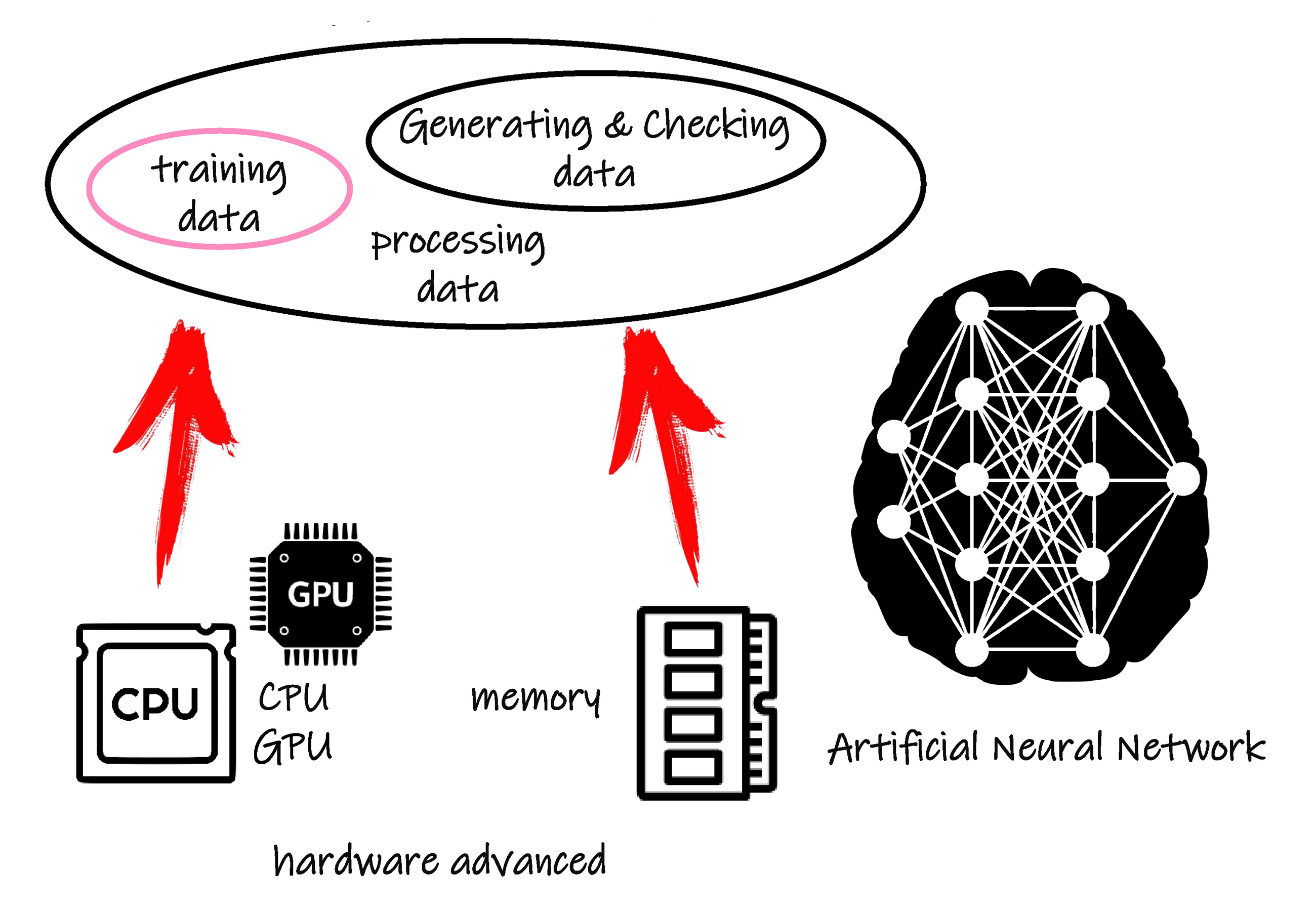
但是学习的过程应该是一个终生的过程,在校成绩的优异仅代表学习的基本成功,并不能完全反映一个人,在这里就是人工智能设备的工作能力。实际使用中,人工神经元网络模型仍然需要根据新的数据提取新的特征,不断完善模型内部的参数。社会这个大熔炉比我们在学校学习到的知识要丰富和实际。
人工神经元网络技术很早就被提出,早期就得到了很好的发展和应用,但由于当时计算机运算处理能力等的限制,随着人工神经元网络规模的增大、结构的复杂化,以及大量的样本信息,造成了建模过程非常缓慢,使其发展曾经受到了很大的制约。
近十几年来,计算机硬件技术高速发展,特别是高频处理速度的 CPU 和 GPU ,使得人工神经元网络建模的运算速度得到了保证。网络技术的普及、大规模存储器和云端存储技术的发展、手机等智能终端的广泛应用等,为大数据的形成奠定了基础,即为人工神经元网络模型的训练和建立提供了更加丰富的样本。注意丰富的含义包括大量和多样两个方面。因此含有多个隐含层等特性的复杂神经元网络的建立成为了可能,基于多个隐含层等复杂神经元网络使人工智能设备的深度学习功能得到了较好的应用和发展。
当前市场上有很多最新技术的深度学习模型架构,绝大部分都是开源的,并且不需要理论和过深的专业知识,普通技术人员就可以凭借这些架构工具开发自己的人工智能设备,常见的有:

Google 公司的 TensorFlow 采用矢量流技术完成自然语言处理、语言、图形和手写文本识别,已经被 Google , Intel , Twitter , Airbnb 等大型公司广泛使用。
Keras 意为将梦境化为现实的“牛角之门”( Gate of Horn ,希腊语中 horn 与 fulfil 含义相近 ),也是基于矢量流技术,并且弥补了矢量流技术的某些不足,其简单易用,不需要复杂的二次开发代码。
Caffe2 可以高速处理高达4千万像素的图像,其具有表现力的网络结构同样使模型的二次开发不需要杂的代码,在图像识别领域功能强大。
Facebook 公司的 Pytorch 简洁、灵活,便于定制个性化,整个训练过程简单易学。
Microsoft 公司的 Microsoft Cognitive Toolkik 可以高效地训练递归神经元网络和卷积神经元网络,分析图形、语音和手写文本等。
自然语言处理技术是为了使人工智能设备可以以人类的方式与人类进行交流,并通过谈话、阅读获取信息,包括自然语言的理解和自然语言的产生。

为了开发可以被人工智能设备运用的自然语言技术,首先需要了解我们人类自身的语言,这就是语言学( Linguistics ),人类的语言学是一个内容广泛的学科。在本文中,Camellia Café 简要介绍音素( phonemes ),词素( morpheme ),词位( lexeme )、句法( syntax )、语境( context ),以及语义学( Semantics )和语用学( Pragmatics )等语言学的主要内容,这是开发人工智能设备语言智能技术的专业知识,就如同 Camellia Café 一再强调的一样,人工智能技术不仅需要电子硬件、算法编程软件等技术,更需要其所应用和服务领域的专业知识。
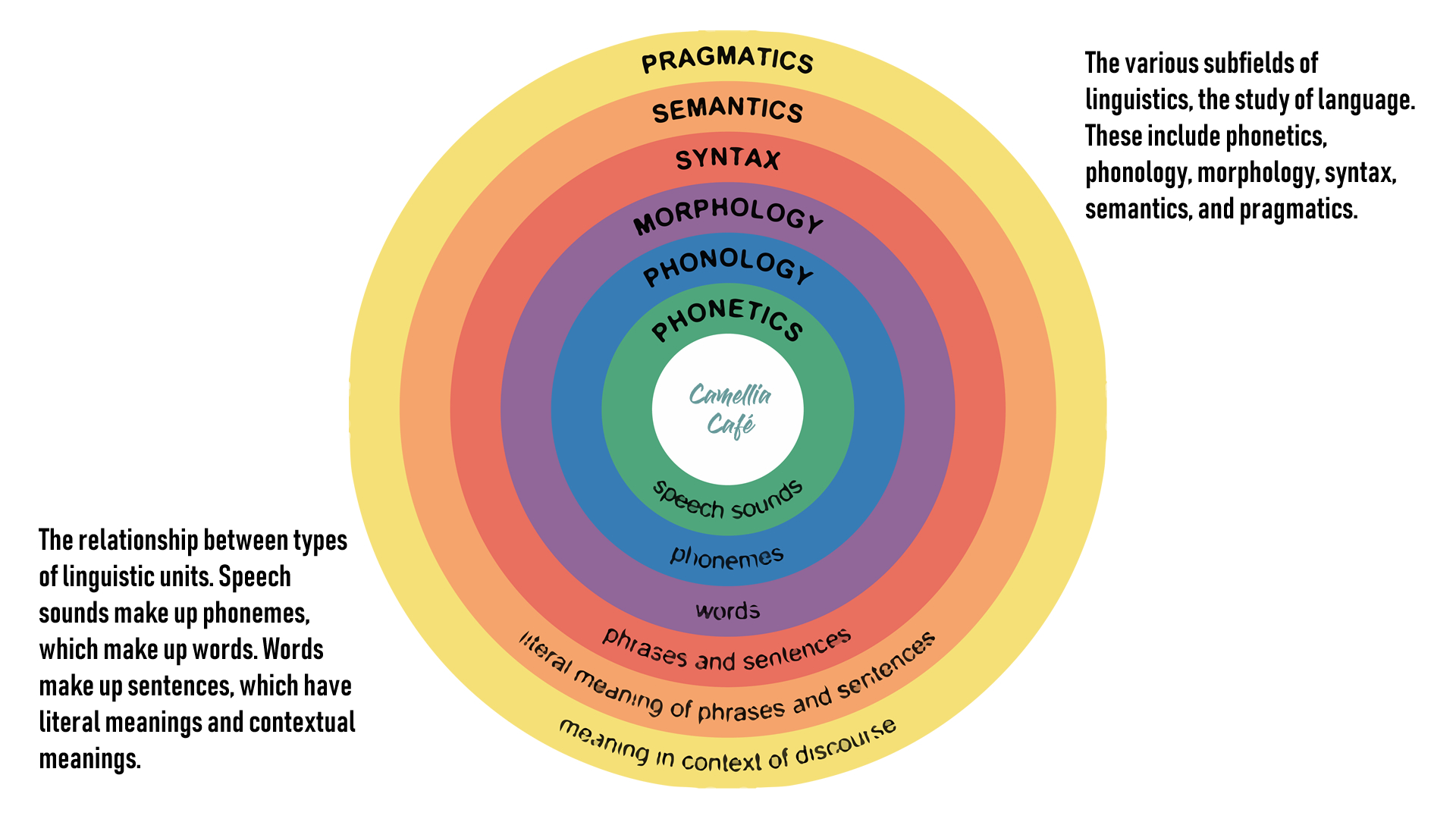
音素 phonemes 是最小的声音单位,用来区分单词,音素自身没有含义,但却能改变一句话的语义。在语言学中,研究音素包括语音学( Phonetics )和音韵学( Phonology )。语音学和音韵学都关注自然语言的声音。

语音学( Phonetics )是从生理学和物理学的角度研究发音的学科,通常可以不需要语言学知识,其研究的对象之一是声音产生的器官,包括嘴、舌、喉咙、鼻子、嘴唇和味蕾等。

音韵学( Phonology )是研究声音特色和变化的学科,通常不同的语言有不同的声音特点,即使同一种语言,同一单词在句子中不同的位置也会有不同的声音。声音变化由多种原因引起,例如气候因素、民族因素等。在英语中,声音的变化包括双元音化( diphthongization )、颚音化( palatalization )、语音易位( metathesis )、元音加入( anaptyxis )、尾音脱落( apocope )、词中语音省略( syncope )、音分裂( vowel breaking)、重复音省略( haplology )、发音同化( assimilation )、发音异化( dissimilation )等。音韵学在语言学中扮演着重要的角色,是单词和词态学的重要基础。
采用音素的知识,在声音中辨识单词就是语言识别,把一系列单词转化为声音就是语音合成。
词素 morpheme 是最小的内容单位,具有语义,有时可以单独存在,有时不能单独存在;而单词 word 同样是最小的内容单位,以不同的形式蕴含不同的含义。研究这些内容的就是语言学中的语态学( Morphology ),其主要内容包括研究构成单词的组分,单词的分割等。单词可以由一个或多个词素构成,但是词素不能够被再次分割。
例如单词 teachers 可以分割为 teach 、 er 、 s 三个词素,其中 teach 可以单独存在,而 er 和 s 各自都不能单独存在。
词位 lexeme 是一个单词的多种变形集,但是这种变形通常不能改变词义和词性。
例如 teach 变形为 teaches 、 taught 、 teaching 都属于词位变化,但是 teacher 却不属于词位变化。
句法 syntax 是单词 word 或词组 phrase 构成句子,以及句子中单词之间结构关系的一列规则。
不同国家的语言句法不同,在英语 English 中,具有同样含义的单词在句子中不同的顺序会引起不同的句子含义,而在芬兰语 Finnish 中,却不以单词的顺序来表示不同的含义,其顺序仅起强调作用。
语境 context 是研究如何表达特定含义,通常包括单词 word 、肢体语言 body language 和音色 tone of voice 等。同一个含义,采用不同的单词,运用不同的手势和体态,发音中重读不同,都会表达出不同的信息。

例如在英语中,大笑着说出 Awesome!, 就表达了兴奋之情,而转动着眼珠、双臂交叉抱胸,挖苦地说出 Awesome... ,可能就表达了冷漠可怕之意。
语义学 Semantics 一方面研究单词 word 和词组 phrase 的含义,即词汇的语义( lexical semantics );一方面研究多个单词或词组组合成的含义,即组成语义( compositional semantics )。
例如在英语 Many cute bears are in Camellia Café. 中, Camellia Café 已经是一个地方的名称,就是组成语义。
语用学 Pragmatics 研究语言表达者的初衷和其所使用的语言之间的关系,语言表达者所采取的表达方式等。“话有三说,巧说为妙”,“一语双关”,“婉转地批评”,“不带脏字的辱骂”等都涉及语用学。因此语言的含义不能仅看语言的表面含义,还与表达方式、说话的时间、地点、环境等相关,可以说没有语用学的知识,就不能正确理解语言的含义和本意。

例如在英语 Could you pass the coffee? 中,仅从字面理解,就是物理动作上的完成一个命令,但是其实际含义却是请求帮助传递一下装有咖啡的杯子,因此正确的回答应该是 Yes, with pleasure! , 而不是单纯的 Yes! 。
再例如在英语 What time do you call this? 中,字面含义是几点了,对应的回答是几点几分,但实际上却是发问者在责怪对方迟到了,因此正确的回答应该是道歉和解释。
具备了一定的语言学知识的基础,让我们开始了解自然语言处理技术。
当前,自然语言处理需要实现的功能主要有:
自动翻译 Machine Translation 每种语言的语法、句法各不相同,表达不同含义的单词用法也不相同,将一种语言准确地翻译为另外一种语言,并能够达到 “信”、“达”、“雅”的效果。
拼写检查 Spell Checking 人工智能设备已经建立了多种语言的规则库,不但能够对人类编写的句子、文章进行单词编写正确的检查,还能进行词义和语法的检查,并能给出句子、文章修改的建议。Word 的该项功能已经相对成熟,微信公众号的在线编辑也具备了该功能。而一些专业软件不仅能够实现拼写错误、语法错误的检查,还能够在遣词造句等方面提供指导意见。
关键词搜索 Keyword Searching 根据人类要求或整句、整段文字的内容,提取文中的关键词汇。
信息提取 Information Extraction 根据整句、整段文字的内容,提取关键信息,精简语义。
语音识别 Speech Recognition 在与人类的交流过程中,提取每一个单词、每个语句,以理解人类说话的内容。
人际交流 Chat 不但能够识别、理解人类说话的内容,还可以根据这些内容,做出反馈,写出、显示或说出语言。
情感分析 Sentimental Analysis 通过人机交流,人工智能设备判断人类说话的内容、语气和语调或编写的文字内容及含意(非含义)等,初步判断交流对象的情感。当前的情感分析仅是从文字和语音方面进行分析,即还处于弱人工智能阶段,后文将展望相关技术强人工智能的发展。

根据语言学的知识,使人工智能设备具备自然语言处理能力,通常采用两种方式:一是手动向机器输入语法、语义、发音等规则,建立规则库。机器根据输入信息,在规则库的判断下,产生输出信息。这是一种自上而下的数据处理的技术方案,即以规则直接处理数据。这种方案,需要充分的、全面的规则,被全部输入到人工智能设备中,是一种白箱模型,工作效果较好,但是在人工智能设备的建设过程中人工输入工作量非常庞大。

二是向人工智能设备输入大量的语义库样本,使人工智能设备结合统计信息或自动学习等方式掌握语言规则,建立自然语言模型,而将机器学习技术,特别是以复杂人工神经元网络为基础的深度学习技术的充分应用,就是发展人工智能设备语言技术的重要一环。这是一种自下而上的技术方案,即通过学习掌握规则后,对数据进行分类,是一种黑箱模型,建立过程的人工工作量较小,但是当模型输出结果出现偏差时,需要采用新的样本数据重新学习。
由于人工智能设备自身的特点,在建立模型的过程和实际使用过程中,会产生多种输出结果,因此可能会生成歧义,包括词汇歧义和句法歧义等。因此自然语言处理中最关键的问题是消除歧义( ambiguity )。
人工智能设备在处理自然语言时,需要经过以下几个具体的步骤:
符号化 Tokenization
这是自然语言处理的第一步,把一组单词、句子或是一篇文章,分解为单独的符号( token ),以便人工智能设备可以读取到最小的信息。这些单独的符号可以粗略的认为就是单词。

例如在英语中:Camellia likes cute bears. 符号化后将得到4个单词,即 Camellia , likes , cute , bears 。
需要注意的是,符号化过程仅是单独的分解,并不把相同的符号进行归类。又例如在英语中 Camellia teaches in Camellia Café. 符号化后得到5个单词,即 Camellia , teaches , in , Camellia , Café ,4个类别,即 Camellia , teaches , in , Café 。
溯根化 Stemming
把不同词性或多种时态具有相同意思的单词转化为同一单词,例如在英语中把 teaches , teaching , teacher 转换为 teach ,这些同一意思的不同单词仅是增加了一些后缀,因此处理过程相对容易。
还原化 Lemmatization
与溯根化( Stemming )相类似,把不同词性或多种时态具有形同意思的,拼写形式差异较大的单词,且溯根化不能够解决的,转化为同一单词,例如在英语中把 taught 转换为 teach ,这些相同含义的不同单词的拼写发生了较大的变化。
语法标记 Part-Of-Speech Tagging
人类语句的实际表达格式和用于人工智能设备存储的标记化的格式有显著的不同。
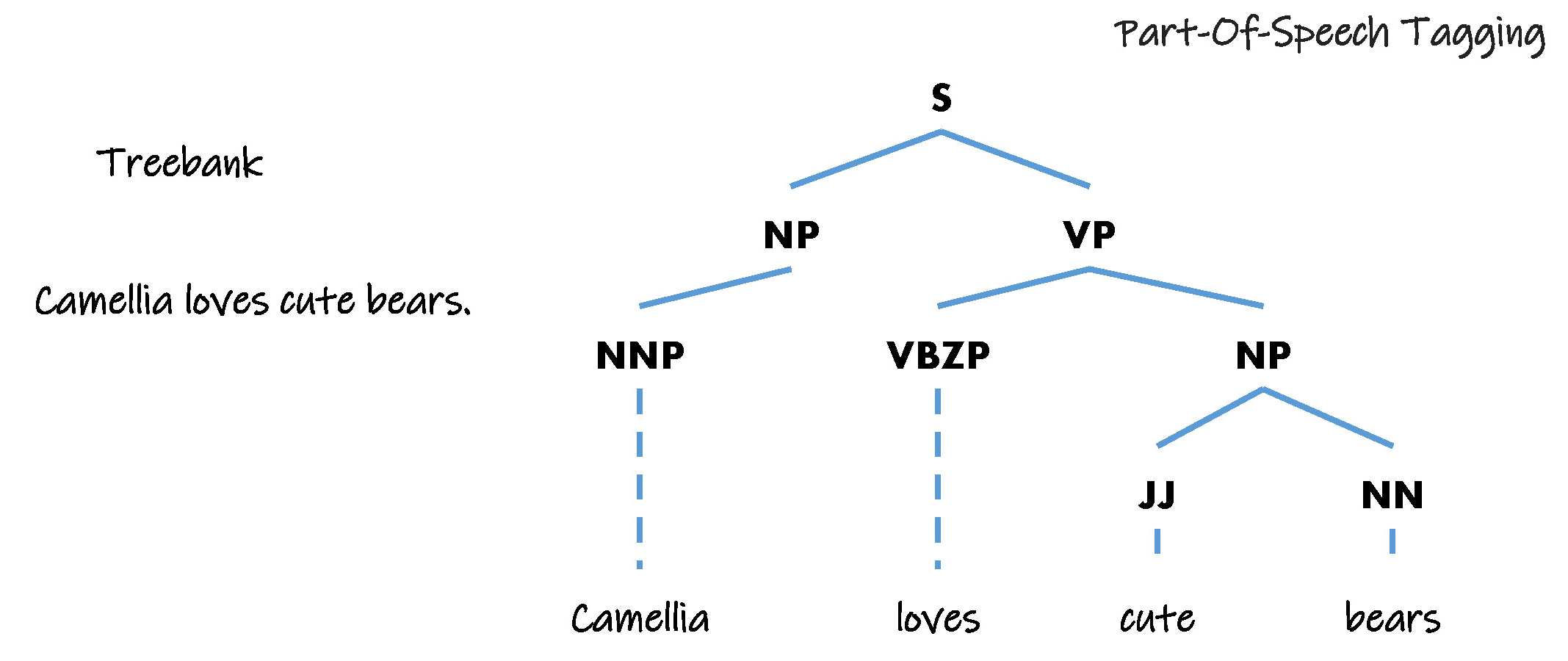
语法标记是对句子、段落进行语法标记,并消除其歧义,其可以用来解释如何在句子中使用单词,即确定单词的名词( Noun - N )、动词( Verb - V )、介词( Preposition - P )、形容词( Adjective - ADJ )、副词( Adverb - ADV )、连词( Conjunction - CON )、代词( Pronoun - PRO )、叹词( Interjection - INT )等的属性。
例如在英语中对 Camellia loves cute bears 进行语法标记,Camellia 是名词, loves 是动词, cute 是形容词, bears 也是名词。
语法标记是一种根据上下文单词词性进行监督学习的方法,英语中最常使用的标记方法是 Treebank 。Treebank 可以由语言学家手动输入规则,或是通过语法剖析程序半自动生成后,语言学家再进行检查和修改,但这都是一个非常大的耗时耗力的过程。
分类信息提取辨识 Named Entity Recognition
对单词进行分类,例如在英语 Camellia likes cute bears 中 Camellia 是人,bears 是动物,在 Camellia teaches in Camellia Café 中,Camellia 是人, Camellia Café 是地方。
大块化 Chunking
把独立分散的信息综合成更大的信息集合。同样是从一组没有结构的文本中,提取信息。大块化不是提取单独的单词,而是提取更有实际意义的短语。
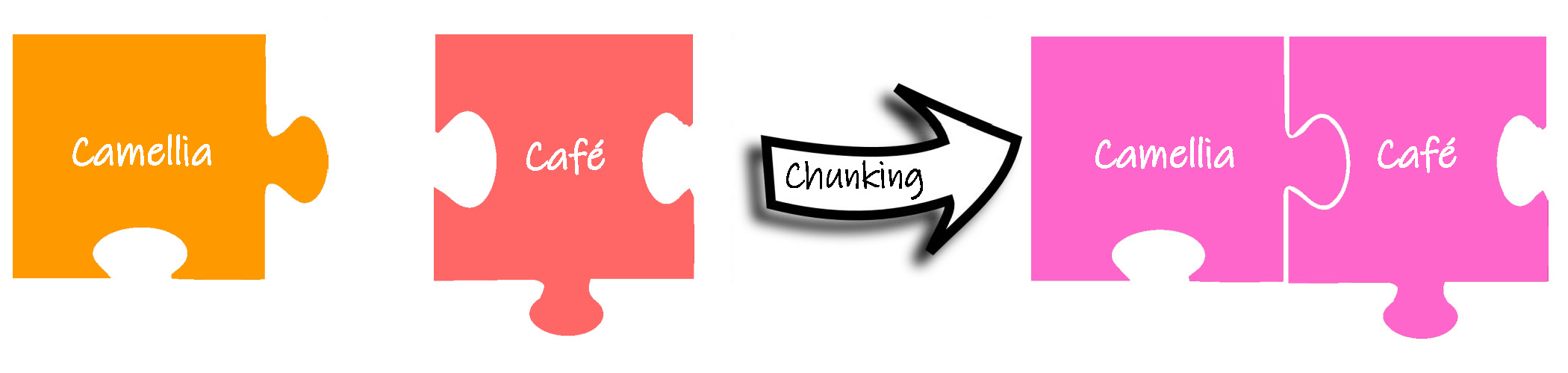
例如在英语 Camellia teaches in Camellia Café 中,不是把 Camellia 和 Café 作为两个单词分别提取,而是作为一个短语 Camellia Café 进行集合处理。大块化是在语法标记的基础上进行的,是对短语而不是单词进行比较,例如有名词性短语、动词性短语等。大块化对于地点、姓名等分类信息的提取过程非常关键。
首先介绍建立单词模型的方法。
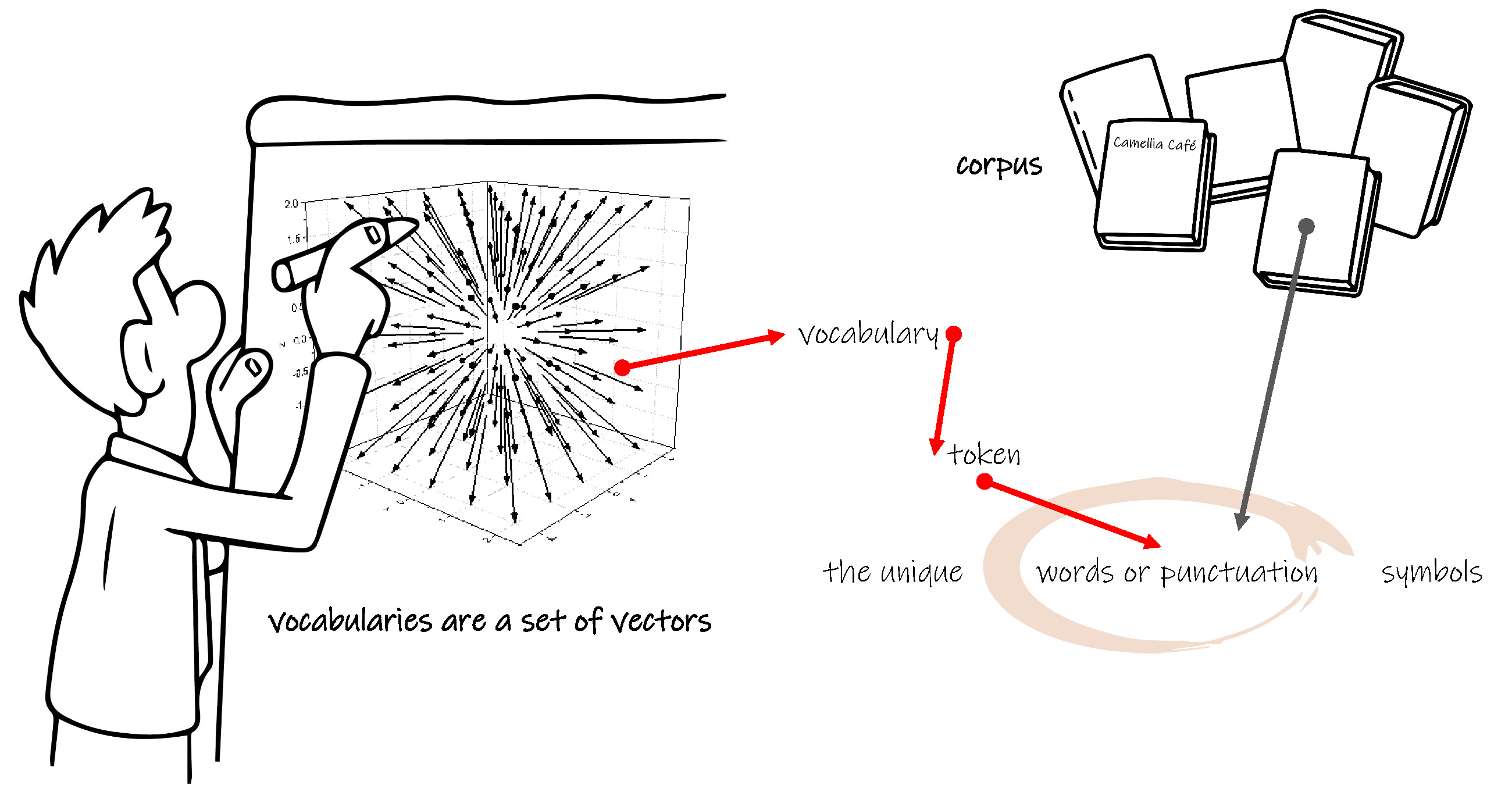
Word2Vec
在人工智能设备内部中,符号化的单词就是单词向量( vector ),每个向量对应唯一的单词。可以采用 1 x n 的矩阵表示单词,对矩阵中的每个权值进行赋值,实现对单词的一一对应。如果需要建立整个字典中单词的向量,按照这种方法,则 n 的取值将非常大,可能是百万级的数量级。所以可以仅针对某句话或某篇文章建立某个单词的向量,由于整句或整篇文章的单词数量有限,n 的取值将大大降低。这称作单词嵌入( word embedding )。例如在英语 Camellia teaches English in Camellia Café. 中,建立的单词嵌入式的单词向量为:
Camellia [ 1 , 0 , 0 , 0 , 0 ]
teaches [ 0 , 1 , 0 , 0 , 0 ]
English [ 0 , 0 , 1 , 0 , 0 ]
in [ 0 , 0 , 0 , 1 , 0 ]
Café [ 0 , 0 , 0 , 0 , 1 ]
通过计算向量之间的数值关系,就可以建立单词之间的联系。在语句和文章中,就可以实现单词的拼写预测、单词查找和情感分析等工作。
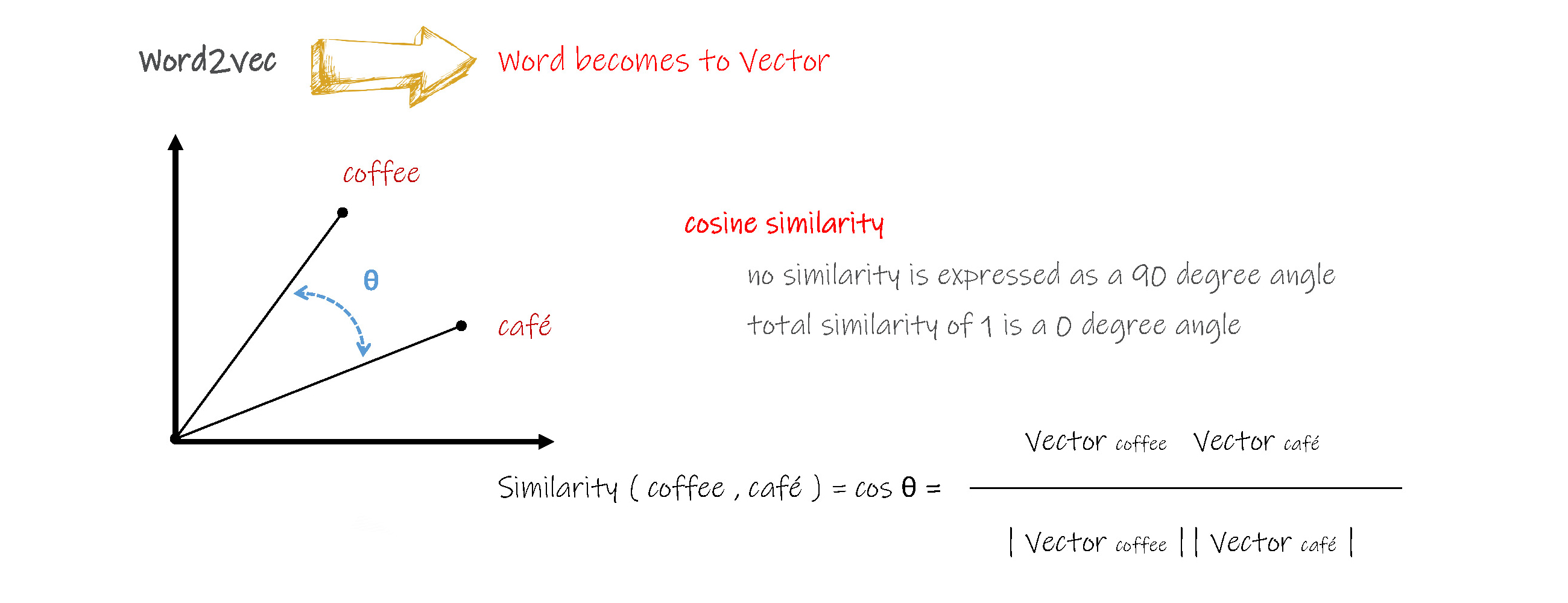
反向思考,虽然从空间的角度观察,每个单词都是一个个离散的向量,但是从单词含义的角度分析,每个单词会有相同、相近或相反的含义,按照这种思路重新对单词进行向量化,即根据单词的含义、词性、句法等特点,分别建立一个向量,形成向量组,即多维的向量,每一个向量就是从多种含义、词性、句法等角度对同一个单词的分别描述。这种 m x k 矩阵,将大大降低每个向量的原有 n 值。
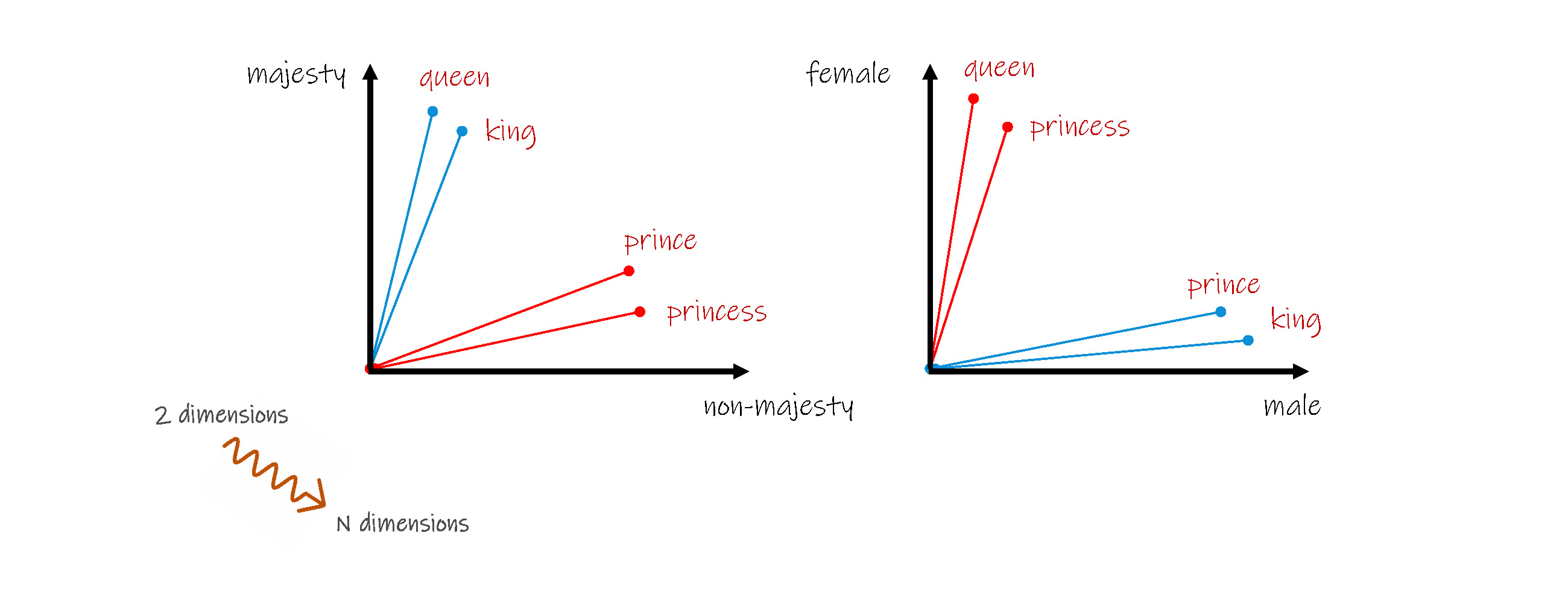
采用这种方法还更容易建立单词之间的关系,例如可以采用两个单词向量夹角的余弦值( cosine similarity )来表示单词之间的相似程度,当夹角的余弦值为0时,表示完全不同,当夹角的余弦值接近1时,表示非常相似。这对后续的拼写预测、单词查找和情感分析等工作的效率将大大提高。
综上,是否可以得出 king - man + woman = queen 呢?
基于夹角的余弦值,我们还可以建立单词相对向量,类似相对密度,以水的密度为标准,其他介质的实际密度与水的密度的比值作为其密度的特征值。应用在这里,就是根据一个基准单词的向量,以及新单词和向量夹角的余弦值来建立新单词的向量,例如在英语中当 coffee 为1,可以得出:
café 为 0.8903,
Espresso 为 0.9812,
Cappuccino 为 0.9105,
Mocha 为 0.9125,
Macchiato 为 0.9035,
Americano 为 0.9635,
……
对句子建模就是给整个句子和句子中的单词分配概率值。
N-Gram
这是一种最简单的句子建模方法,包括对整个句子分配概率值,例如英语中P ( Camellia loves cute bears ) 是整个句子的概率值;以及基于句子中的某个单词之前的单词,来分配该单词的概率值,例如英语中 P( bears | Camellia loves cute ) 是 bears 基于 Camellia loves cute 的概率值。
N-Gram 可以实现:
(1)在噪音无序的环境中辨识单词以及歧义输入,便于进行语音识别和手写文本识别;
(2)拼写错误检查和修改;
(3)辨识句子中的单词顺序,进行机器翻译;
(4)单词预测,增强交际功能。
N-Gram 中的 N 表示具有 N 个单词的句子,例如 2-Gram 就是2个单词序列的句子, 3-Gram 就是3个单词序列的句子……
随机上下文无关语法 Context-Free Grammars
这是一种语法解析的建模方法,就是将一个句子转化为其对应的语法结构。
由于人类的自然语言是一些列的字符串,语言的大部分结构都可以采用上下文无关语法描述来建模,这种方法可以对绝大多数自然语言结构进行建模。
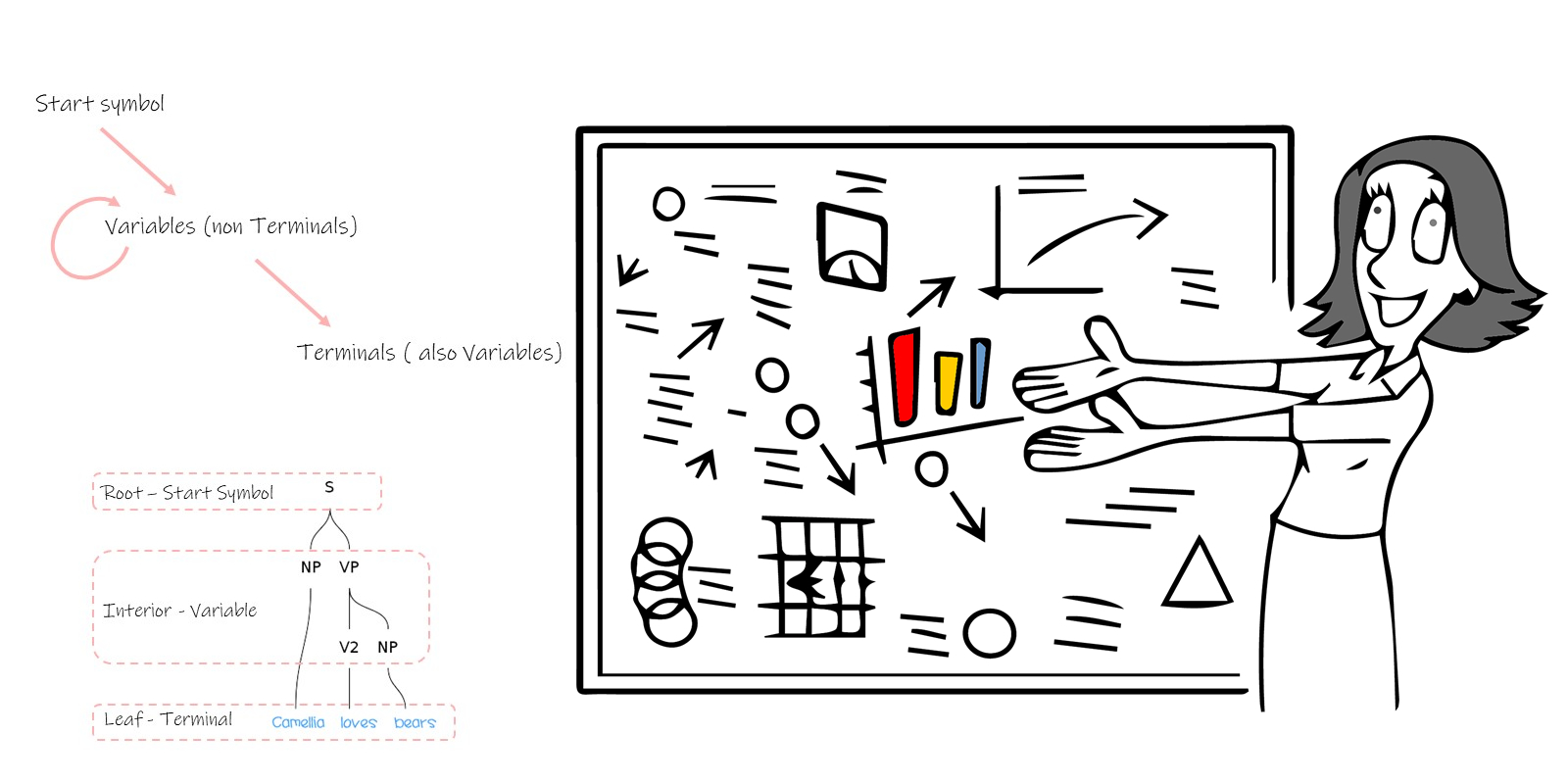
这种建模方法采用三种变量,即开始符号( start symbol ),中间符号( non terminal )和终点符号( terminal )。开始符号就是 S ,中间符号是一组符号,分别代表不同的语法结构变量,终点符号就是单词。
建模方法从 S 开始,根据不同的语法规则,生成多个 non terminal (或包括一个 terminal ) ,每个 non terminal 继续根据不同的语法规则, 生成新的 non terminal 或是 terminal,直到所有的路径最终都变为单词。这种方法很像一棵反向放置的树,因此称作语法解析树( Parse Tree )。
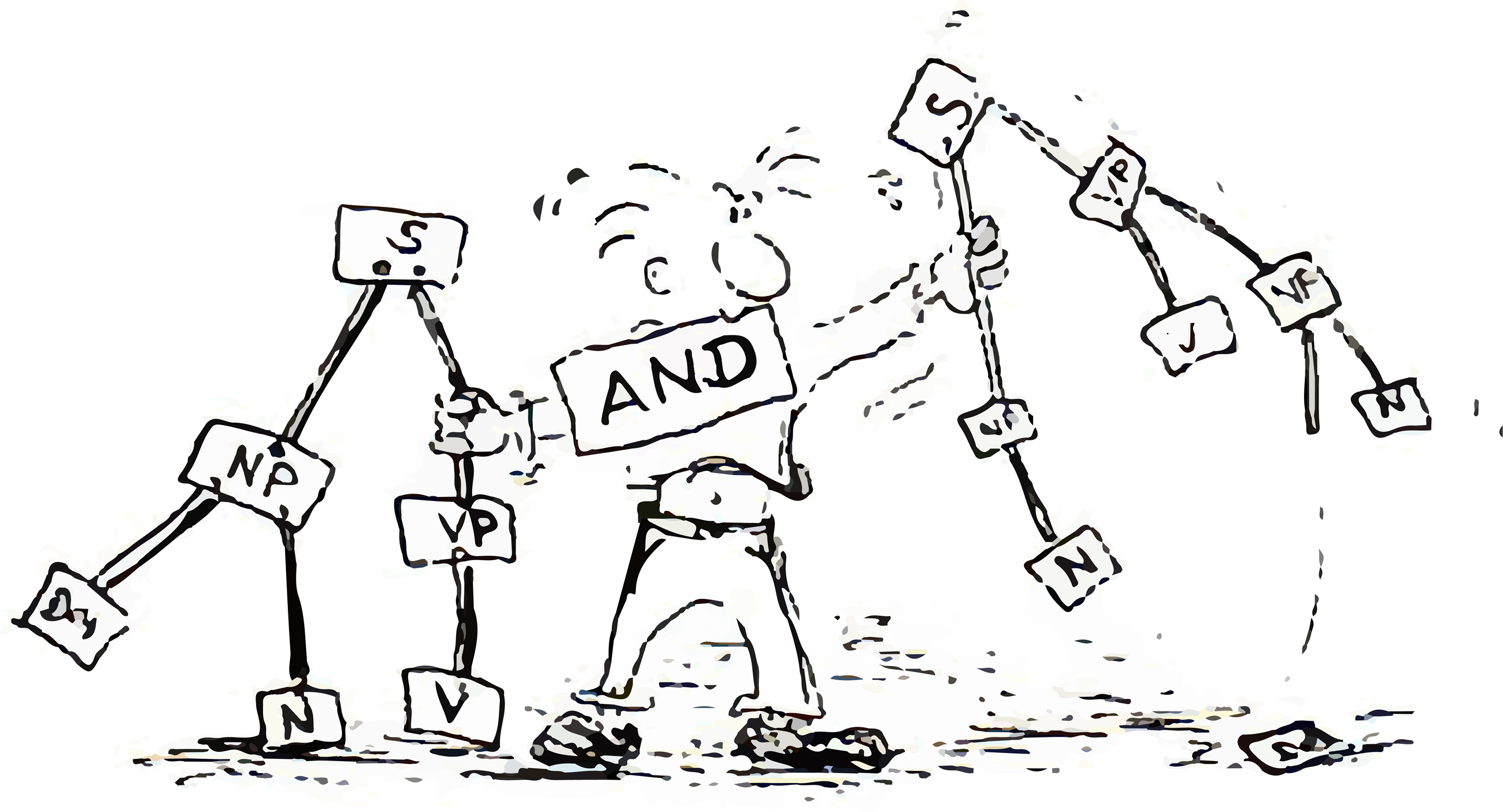
当一个句子经过语法分析后产生多种分析结果时,就会产生结构歧义,例如:
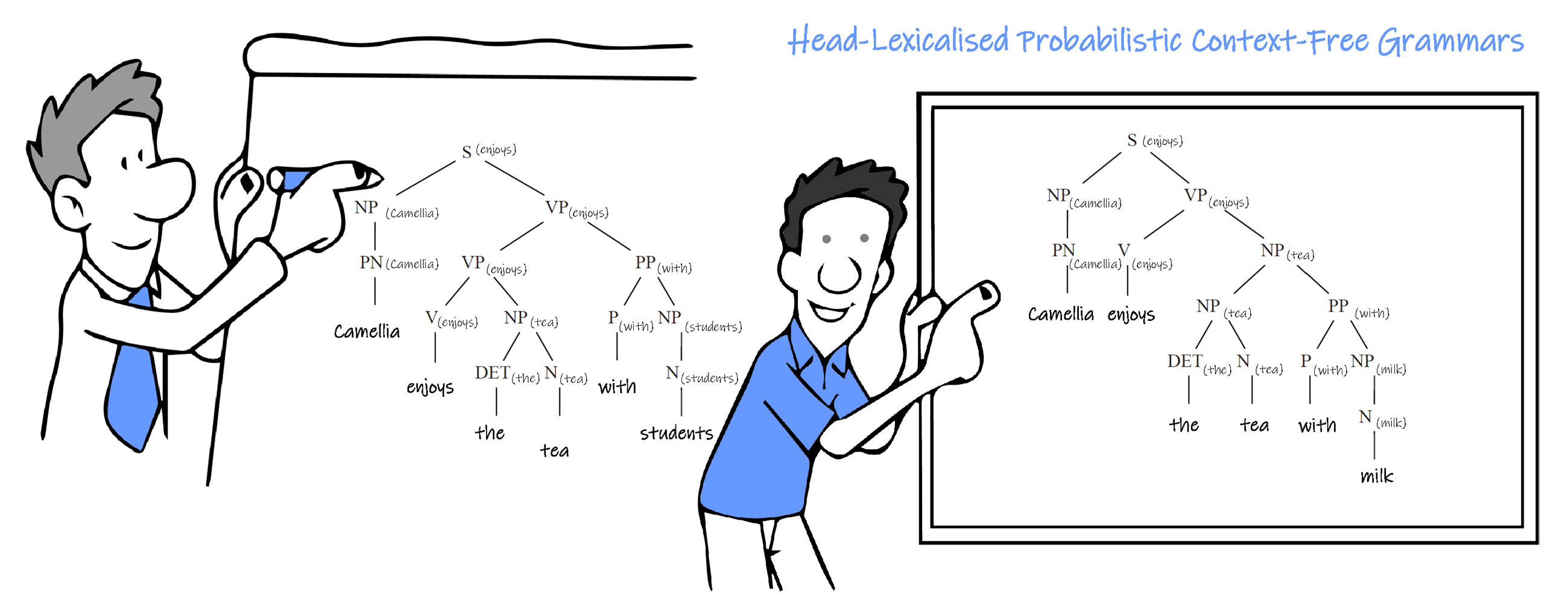
同一个英文句子 Camellia enjoys the tea with milk ,会产生两种分析结果:
下图左侧的意思是 Camellia 喜欢同时喝茶和牛奶(两个杯子分别装茶和牛奶,分别喝);
下图右侧的意思是 Camellia 喜欢喝英式茶(茶和牛奶在一个杯子中混合后同时喝下)。
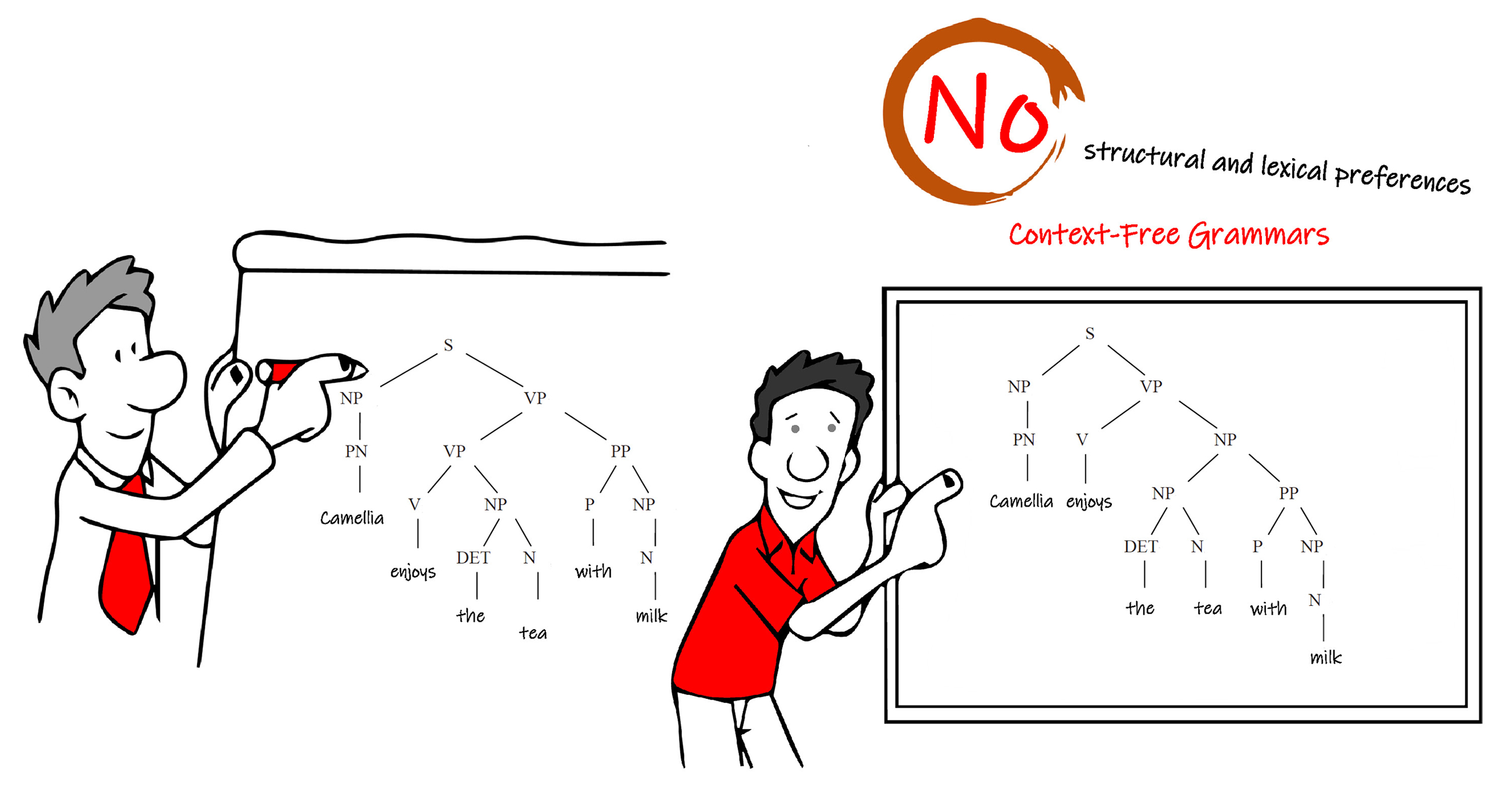
结构歧义通常表现在多种形式中。最常见的两种形式是附加形式歧义和联合形式歧义。附加形式歧义是由于一个特定的组分可以被添加到分析树的多个部位而引起。联合形式歧义是由于不同的词组通过连词连接而引起。
由于产生的多种分析结果没有各自的优先级或正确程度的比较值,这种技术不能使人工智能设备在分析语句时辨析歧义。
此外,语法正确但是语义不合理的分析结果是人工智能设备处理自然语言的最大难题。只有消除了歧义,才能在多个分析结果中挑选出正确的分析结果。有效的歧义消除算法需要统计学、语义学和上下文内容等方法来辅助分析。
概率上下文无关语法 Probabilistic Context-Free Grammars
概率上下文无关语法技术在上下文无关语法技术的基础上,给每一种语法规则分配了一个概率参数,如下图,可以建立不同优先级结构和具有正确度比较值的模型。这些概率参数值可以在样本的训练过程中,学习得到并不断更新。这种技术对于语言识别、机器翻译、拼写检查、人际交际等意义重大。
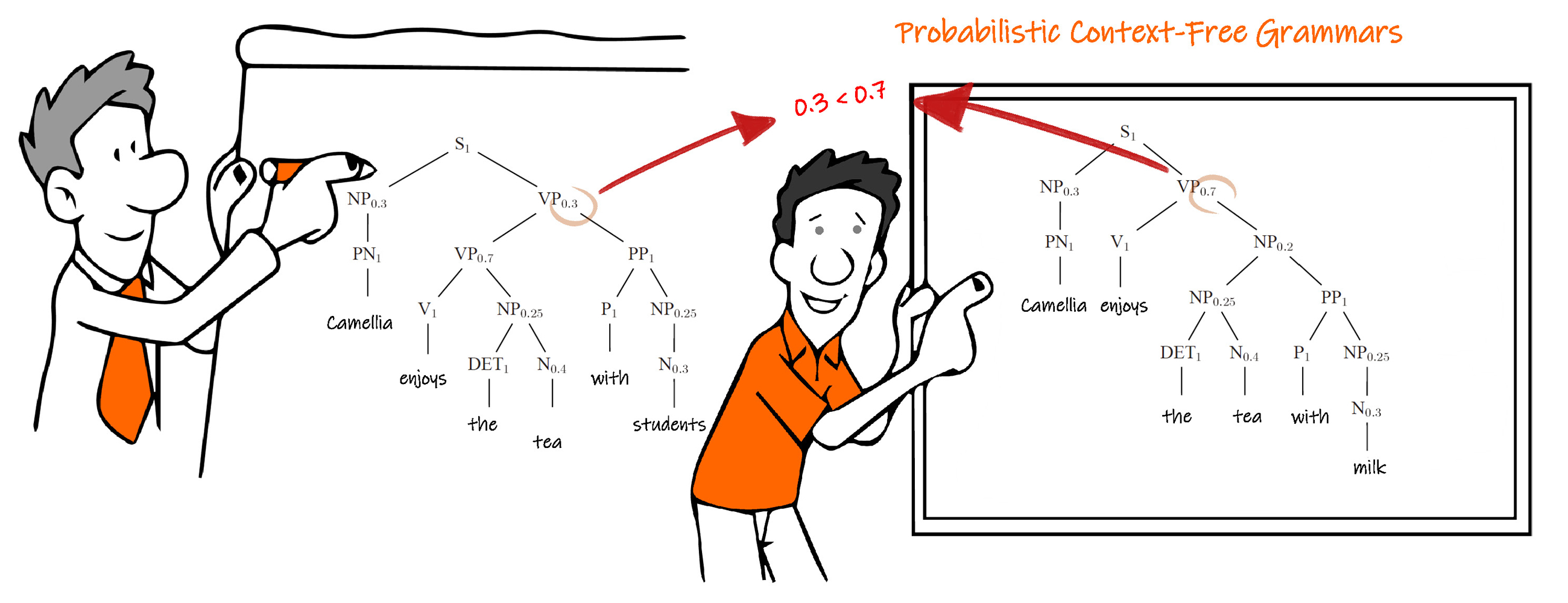
例如同样对英语句子 Camellia enjoys the tea with milk ,产生的两种分析结果,每种句子的概率不同。
但是概率上下文无关语法技术仅是基于语言的结构特性,仅从句法的角度出发,没有考虑词汇的影响,因此仍不能解决带有词汇或词组结构的语句分析的困难。
前缀词汇概率上下文无关语法 Head-Lexicalised Probabilistic Context-Free Grammars
前缀词汇概率上下文无关语法技术在结构分析技术的基础上融入了词汇前缀等信息。把 non terminal 升级为带有词汇标识的中间符号,并进行分类。每个类别都代表一个前缀词汇,并且子类的前缀词汇同样被记录到其母类的前缀词汇中。最终类别的词汇前缀就是最具代表性的单词或单词原形,在概率的基础上,把词汇体现在语法解析树的根部或中间部位,指导后续的语法规则的优先选用。
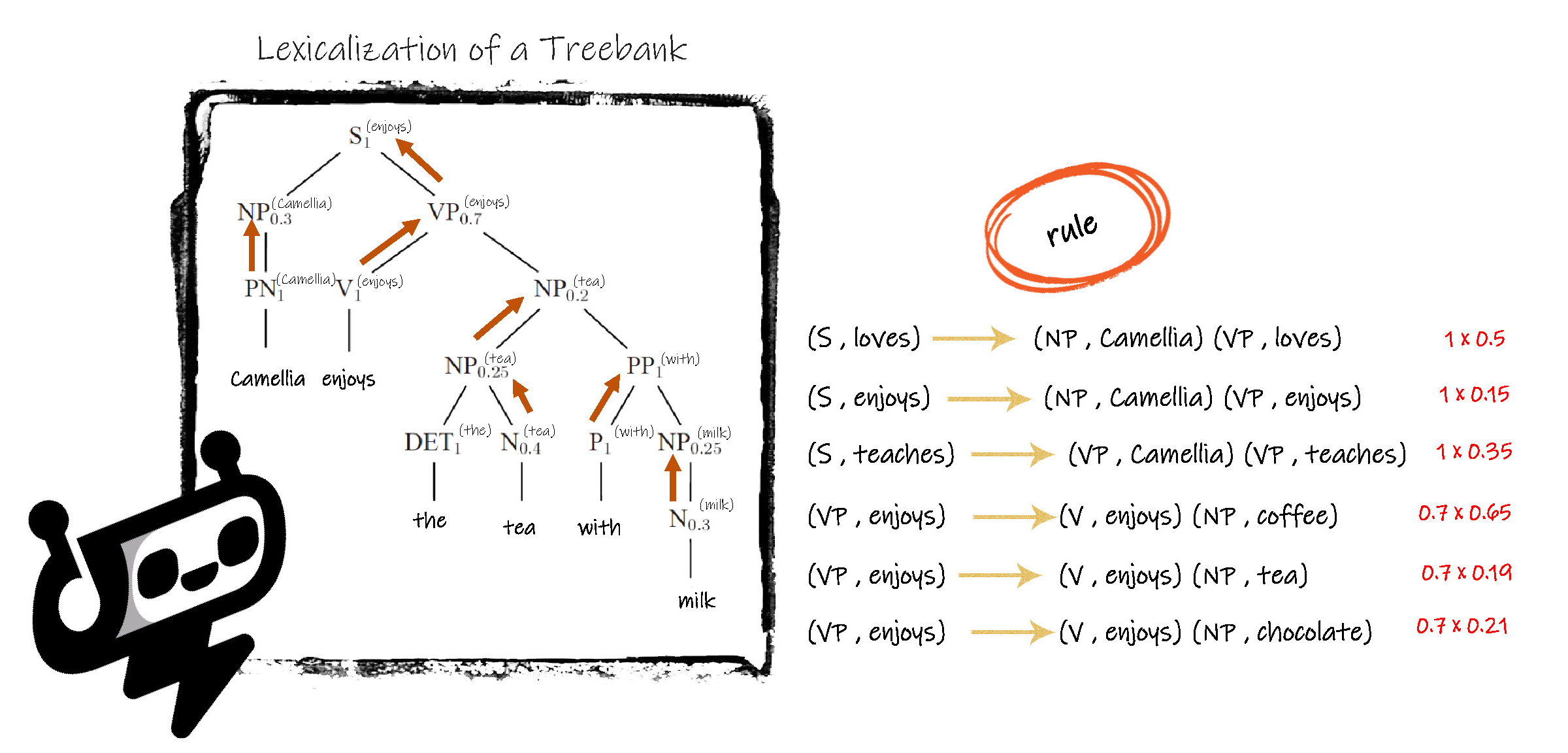
在概率上下文无关语法中, S 的概率值 p( S ) 通常都是1,而在前缀词汇概率上下文无关语法中,根据不同的前缀词汇,有多个 S,并且每个 S 的概率值变为 0 《 p( S, lexical item) 《 1 ;non terminal 的概率值也变为:原有概率值 x 词汇分组概率值。
这样生成的综合概率值,就会使得即使当语法规则A的概率值大于语法规则B的时,只要出现了和规则B组合在一起的高概率值的前缀词汇,人工智能设备会优先选用规则B。其本质是既考虑了语法规则又包含了单词含义。
为该模型分配前缀词汇的方法,需要采用基于语言学专家的经验指导方法结合自学习评估的方法,即半监督的机器学习方式。
先有鸡还是先有蛋
无论是概率上下文无关语法技术,还是增加了词汇概率的前缀词汇概率上下文无关语法技术,获取概率值通常采用以下两种方法:
一种最简单的方法是采用树结构,建立在大量已经分析后语句的语义库基础上。并同时采用动态处理技术,即对于已经验证正确的语法规则,可以随时添加到作为后续分析树的建立规则中,这样将大大提高时间分析效率和存储效率。
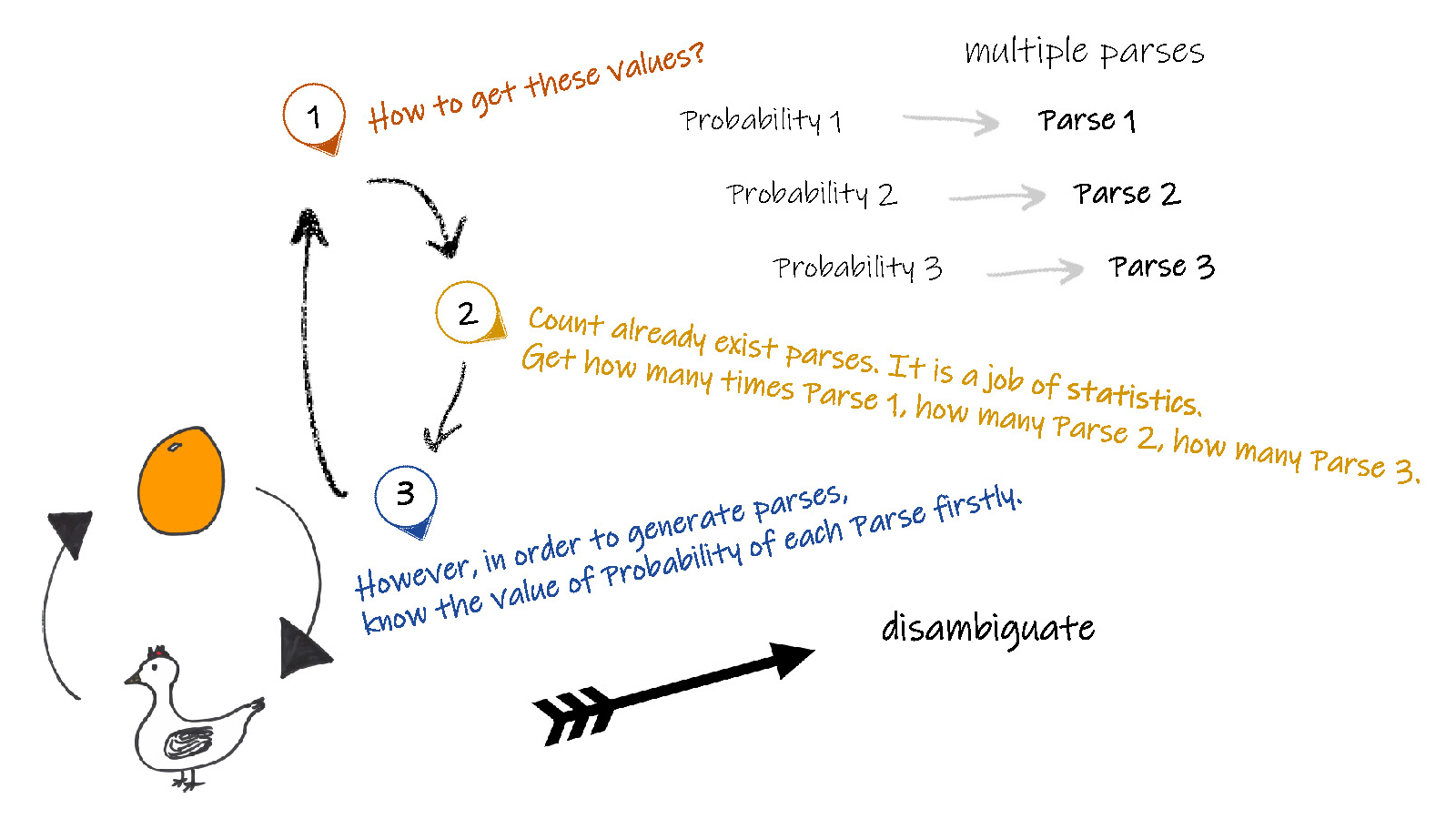
另一种方法,就是自学习。概率上下文无关语法和前缀词汇概率上下文无关语法技术都是为了解决产生多个分析结果而带来的歧义,而对每种分析结果赋予一个独立的参数。但是为了获取这些评价规则的概率值,我们首先需要获取一个已经含有概率参数的分析规则,来开始分析。一方面为了得到没有歧义的分析而需要概率,一方面为了获取概率值而需要已有的分析结果,这似乎是一个先有鸡还是先有蛋的讨论问题。因此需要同步进行,首先赋予各种规则同样大小的概率(概率值的初始化),之后进行语句分析,并根据分析的结果更新各种规则分析后的结果的概率值,之后采用新的概率进行新一次的分析,如此交替反复进行,不断提高概率库信息,并逐步提高分析结果的正确性和非歧义性。
基于深度学习的自然语言处理技术
前文已经阐述了机器学习,其中表征(特征)学习( representation learning )就是让人工智能设备自动地发掘样本的特征值,对原始样本数据进行分类。表征(特征)学习采用有标记的样本进行监督学习,并同时基于未标记的样本进行自学习,以消除监督学习的过拟合( over fitting )现象,即可以很好的满足样本数据的分析,但是对于非样本数据却缺乏分析能力。
深度学习( deep learning )是一种基于复杂人工神经元网络的机器学习技术,可以采用监督、半监督和非监督学习等方式。学习不仅要学习到自然语言规则,还要学习到学习的方法。
前文已经以前向人工神经元网络( Feedforward Neural Network )为例介绍了人工神经元网络的基本知识,前向人工神经元网络就是一种全连接的神经元网络( Full Connected Neural Network )结构。
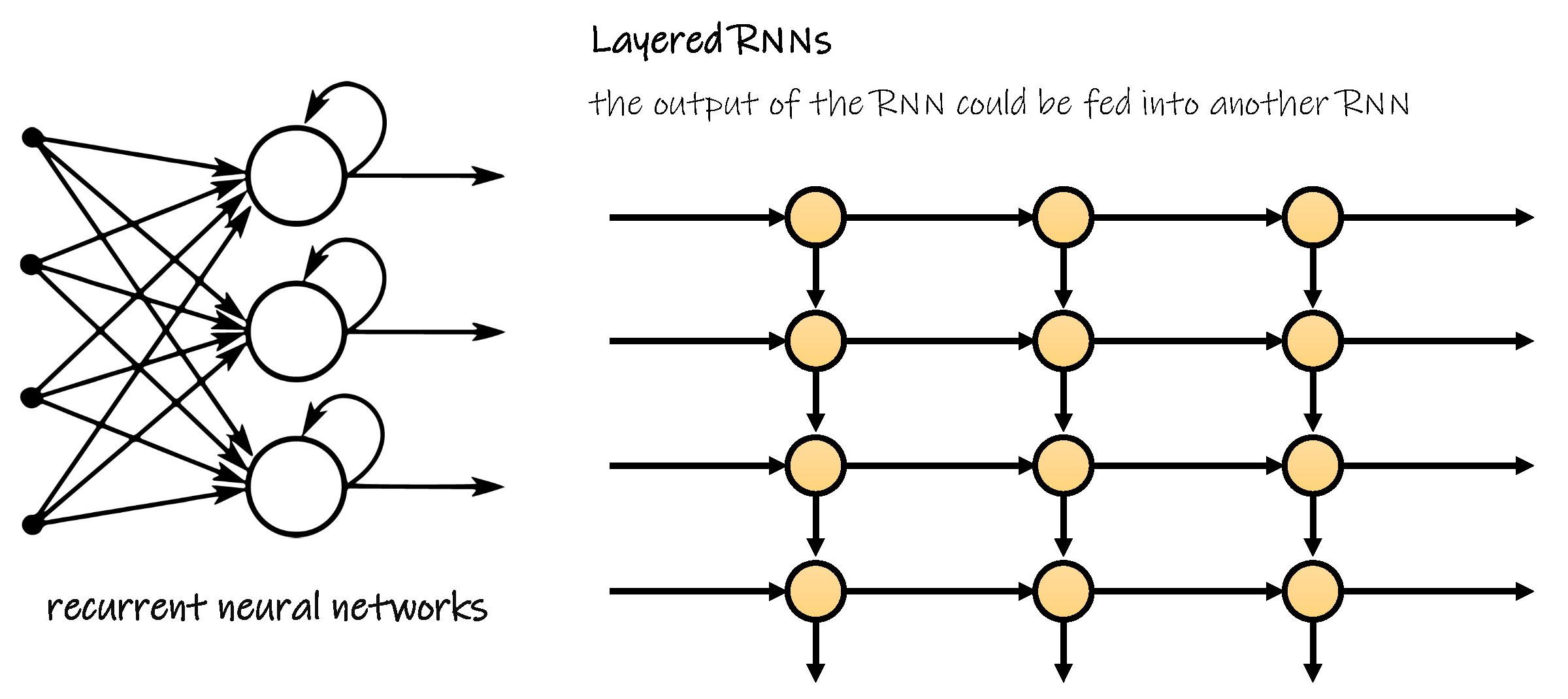
递归神经元网络在前向人工神经元网络的基础上,使某一层的节点形成一个回路,即记录前一时刻的输出值,体现一种迭代的思路,因此该节点的输入不仅具备前一层的加权和信息,还具有非线性功能。
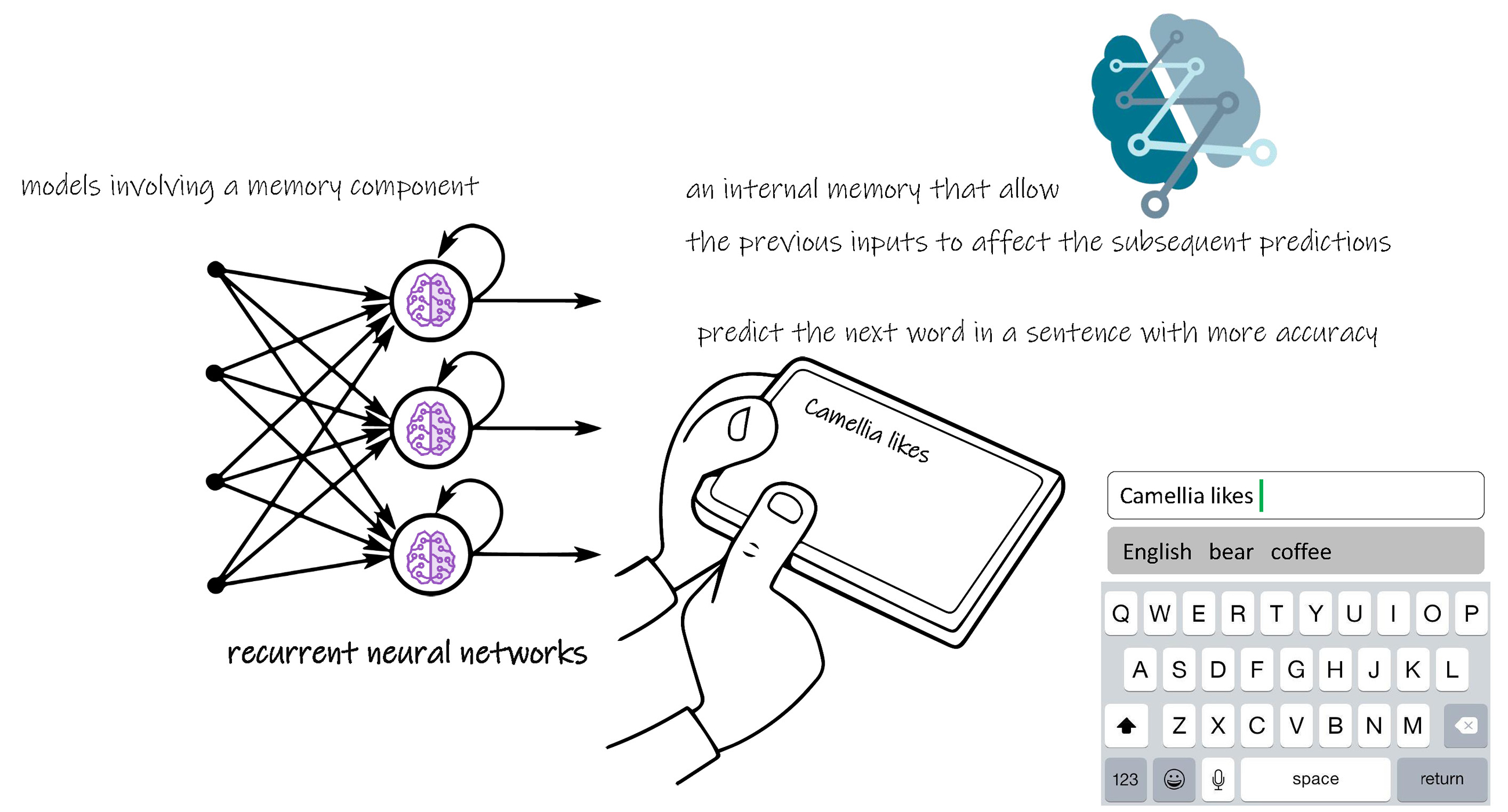
这种网络结构更贴近人类的思维,每一个节点就好似融入了一个存储器,与前一时刻的信息密切相关,因此在语言产生和组织语言顺序中功能强大,可以较好地实现写和交际等能力。此外,具有该递归结构的节点不局限于网络的某一层,递归神经元网络的输出可以作为另一个递归神经元网络,以建立更加复杂的网络结构,实现更加复杂的功能。
当前递归神经元网络最典型和最常见的应用就是输入法的单词预测。
但是这种网络由于结构复杂,训练或学习难度较大,并且很早前的信息对后续的输出影响较少。
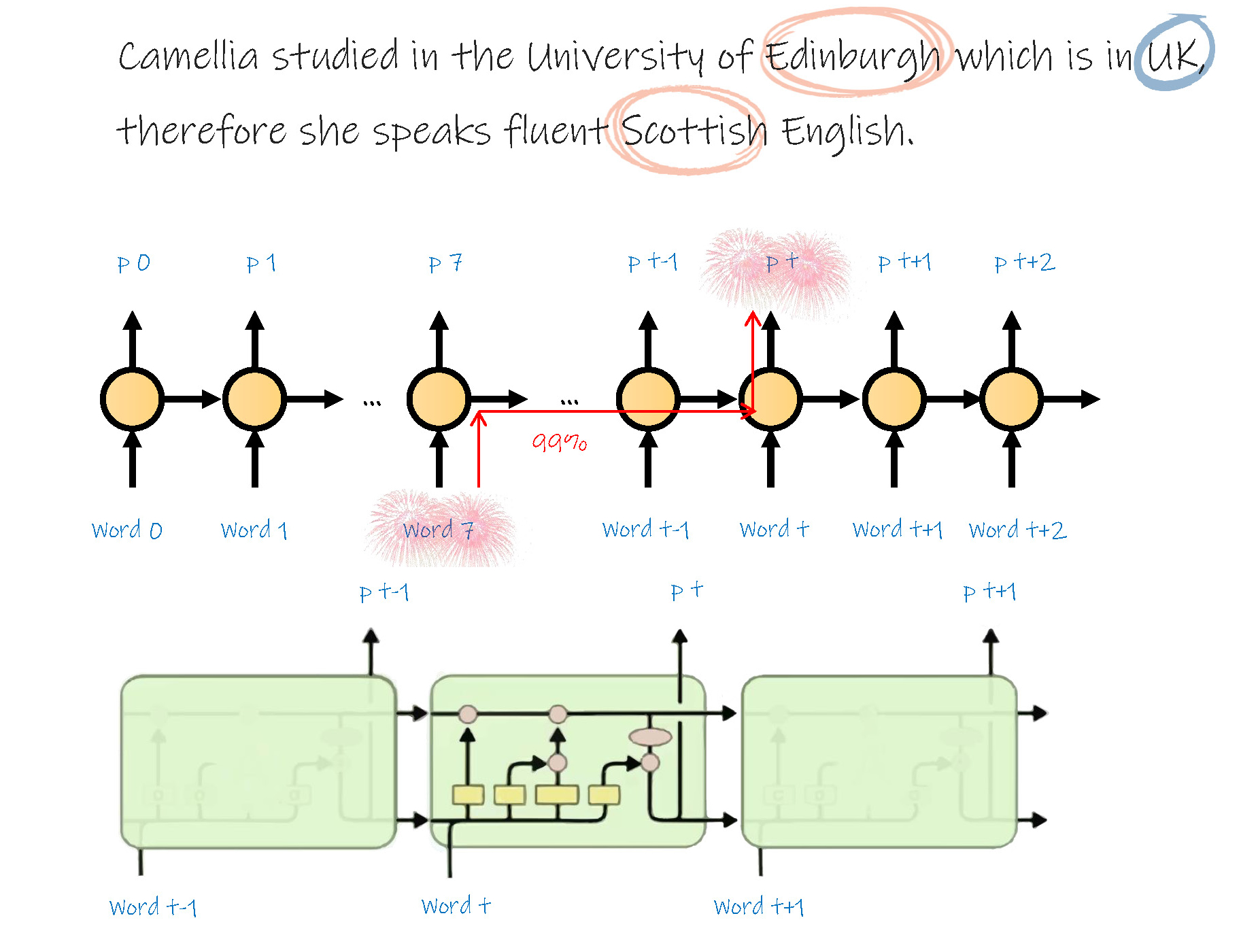
例如在英文 Camellia studied in the University of Edinburgh which is in UK, therefore she speaks fluent Scottish English. 中,由于 Edinburgh 在句子中距离 Scottish 较远,而 UK 在句子中距离 Scottish 较近,因此很难快速准确的根据前文预测到苏格兰英语这个单词。因此在网络结构中增加一些处理门,包括遗忘门和增强门,根据需要,把一些较早前的信息通过增强门更多地传递到输出,而通过遗忘门减少一些临近的信息其对输出的影响。
递归神经元网络也可以运用到语言文本分类中。
卷积( convolution )就是对输入数组的全部或子集进行一种运算,通常是加权和,即把输入数据和称作过滤器( filter )中的参数相乘后求和,以缩小输入数据的维数。
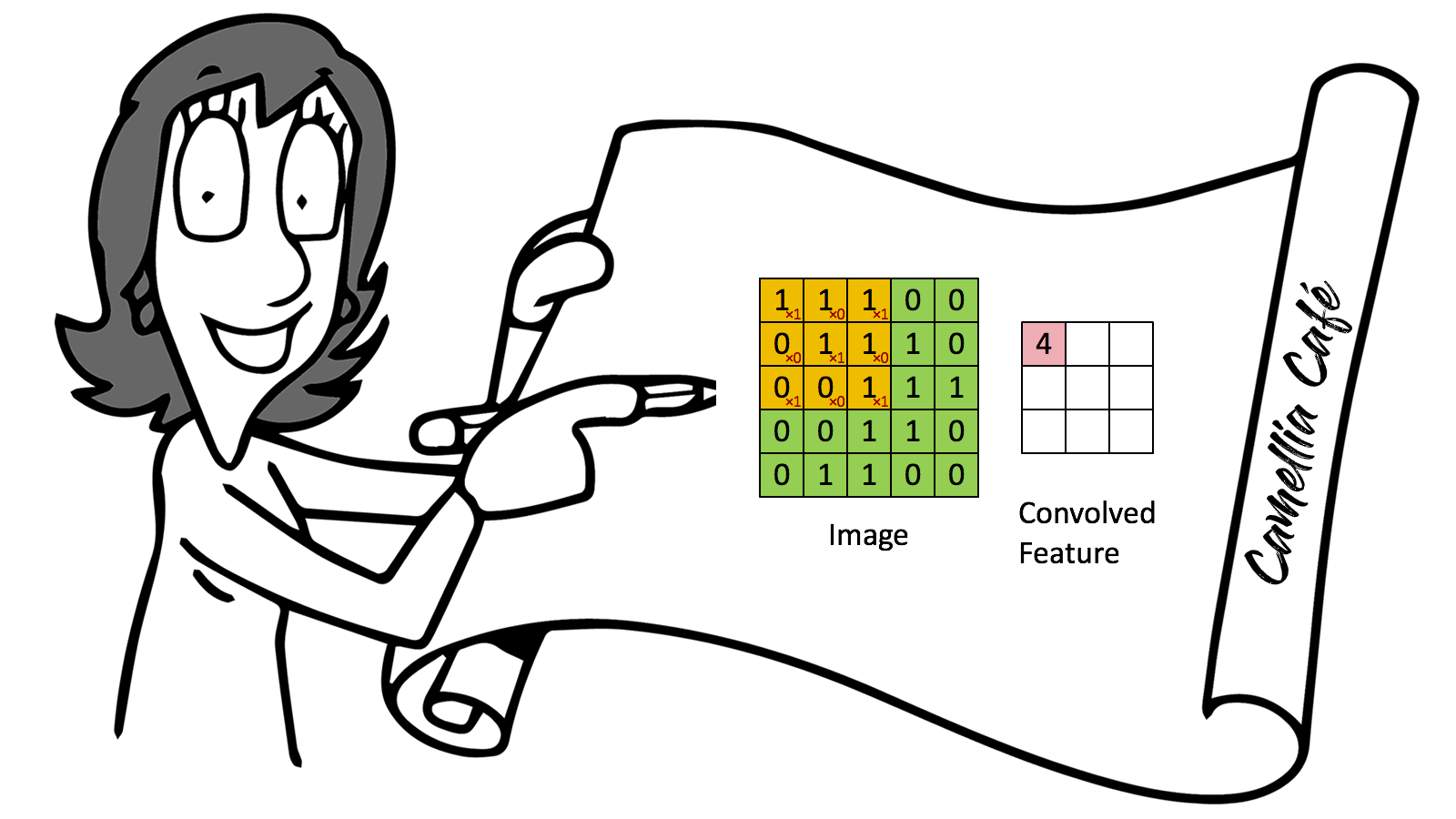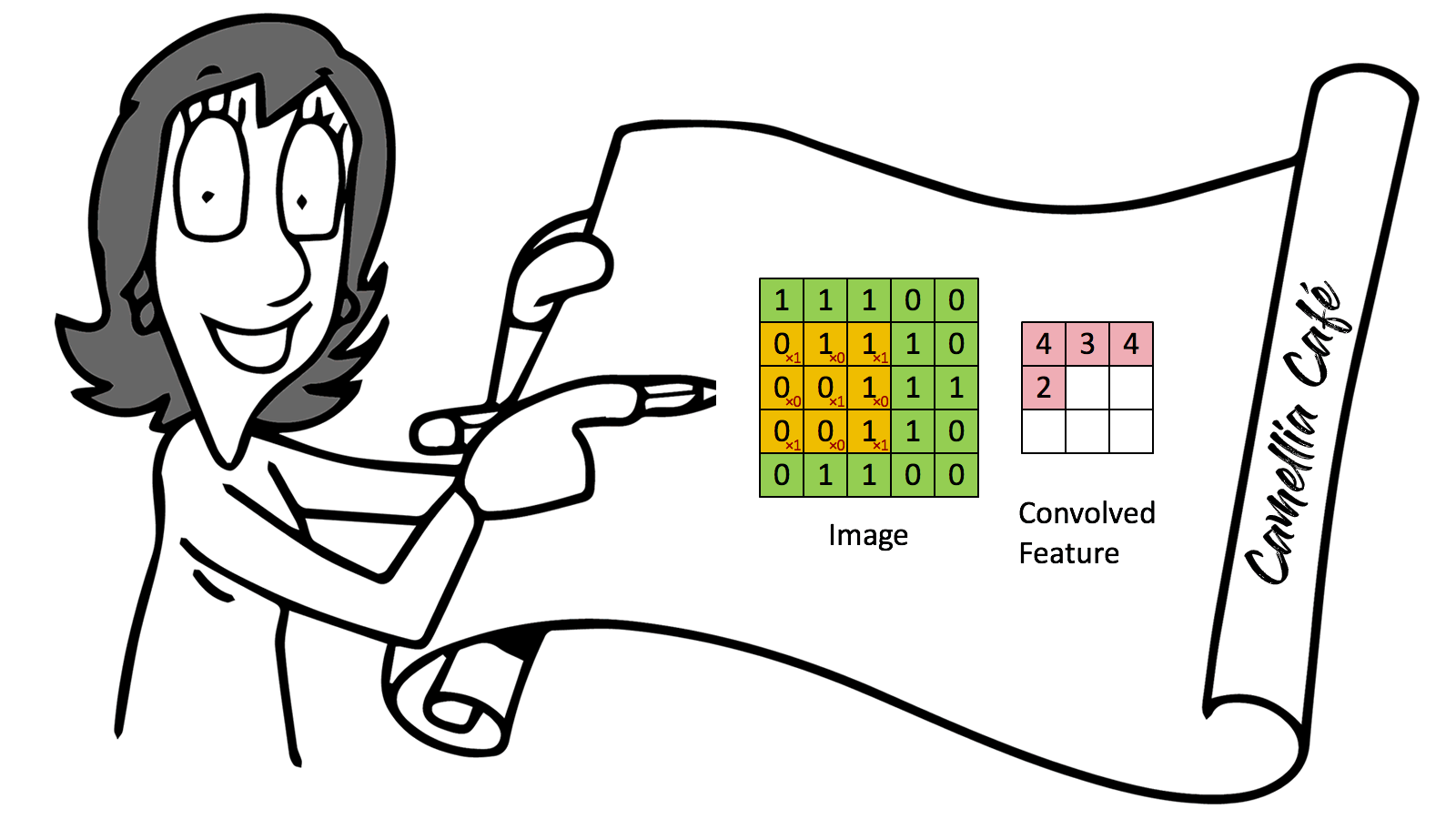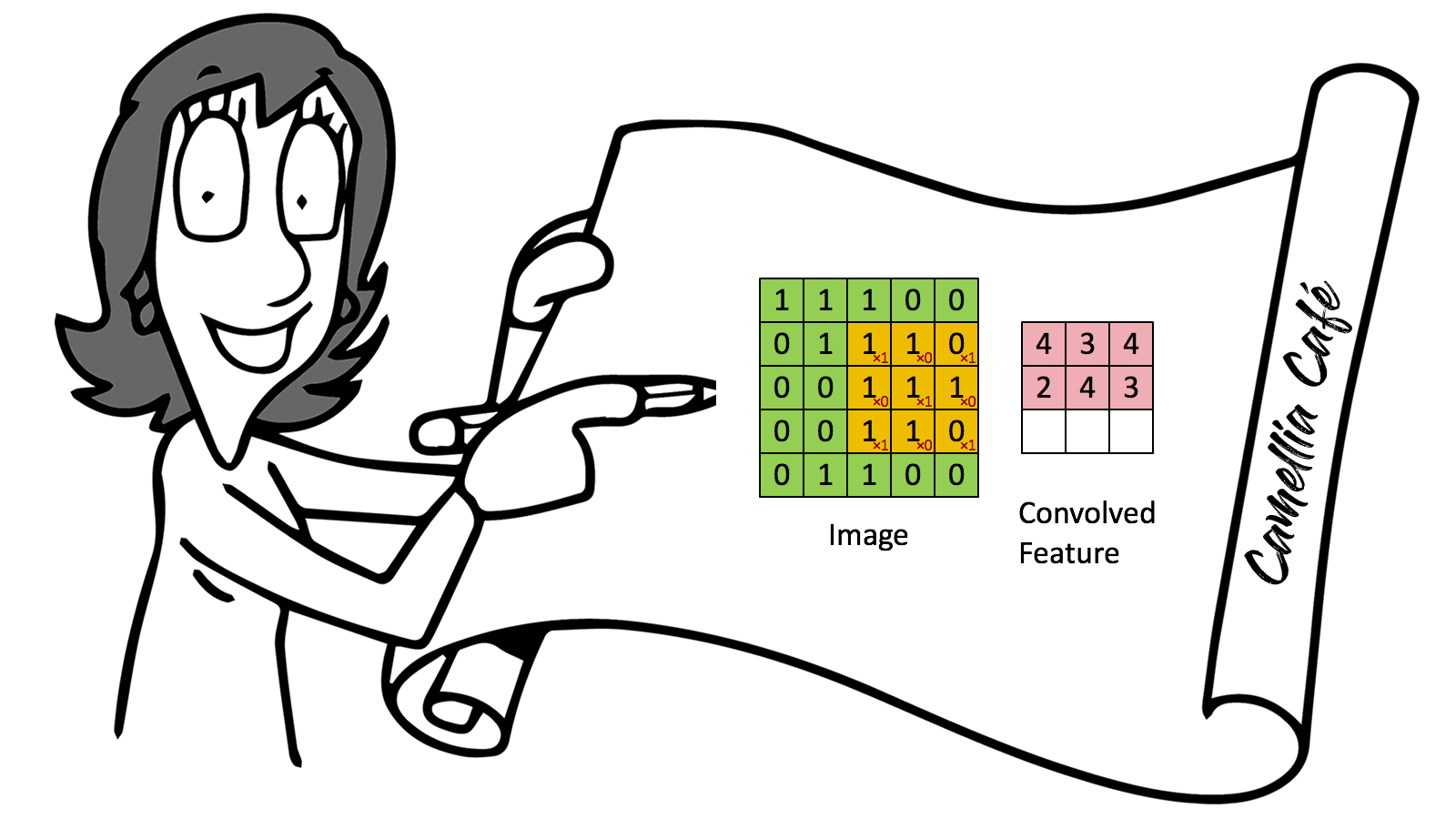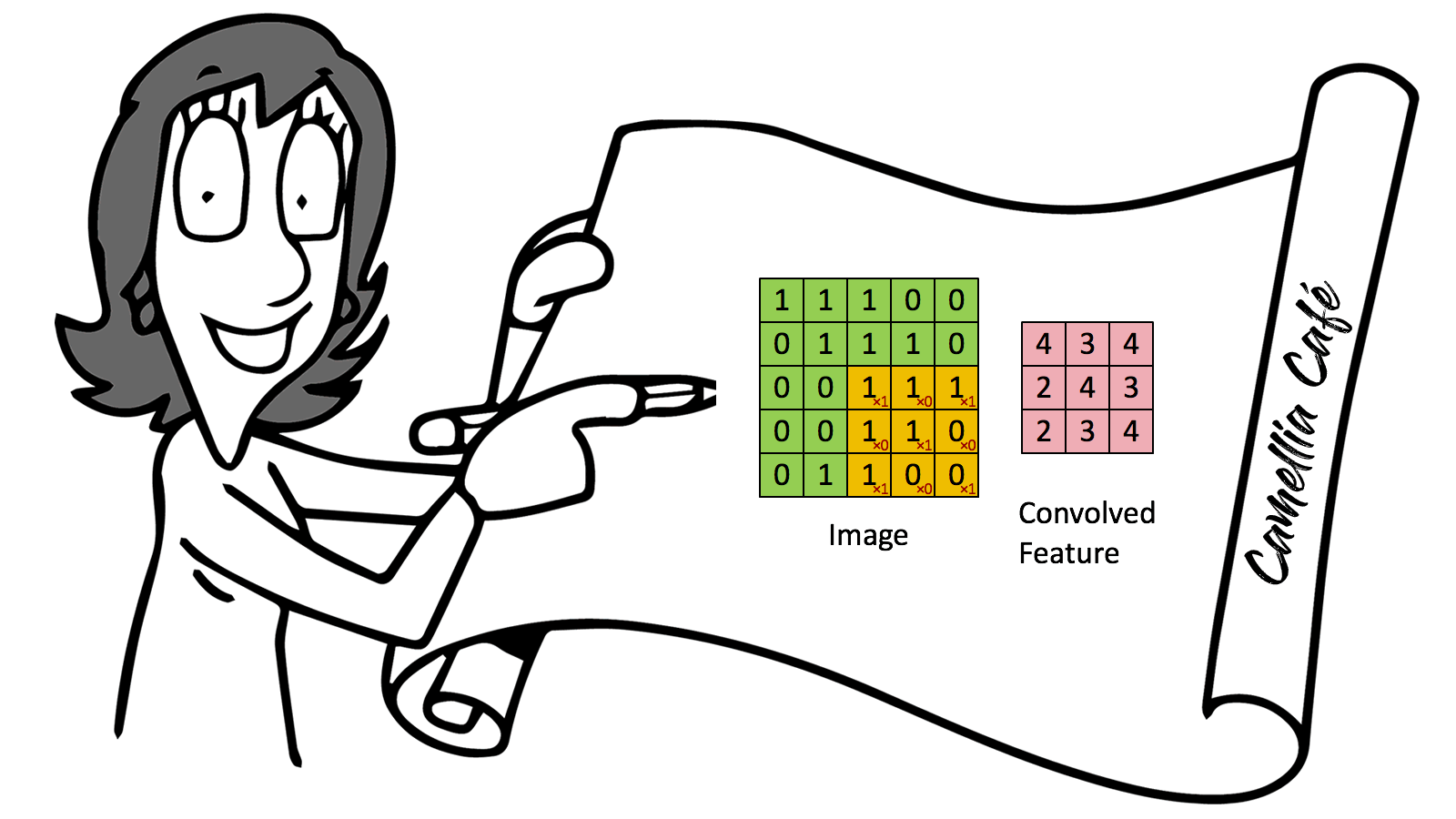
卷积神经元网络最早应用在图像识别中,通过卷积的方式,可以根据图像中不同物体的颜色不同,提取到图像中物体的边缘,进而识别物体。
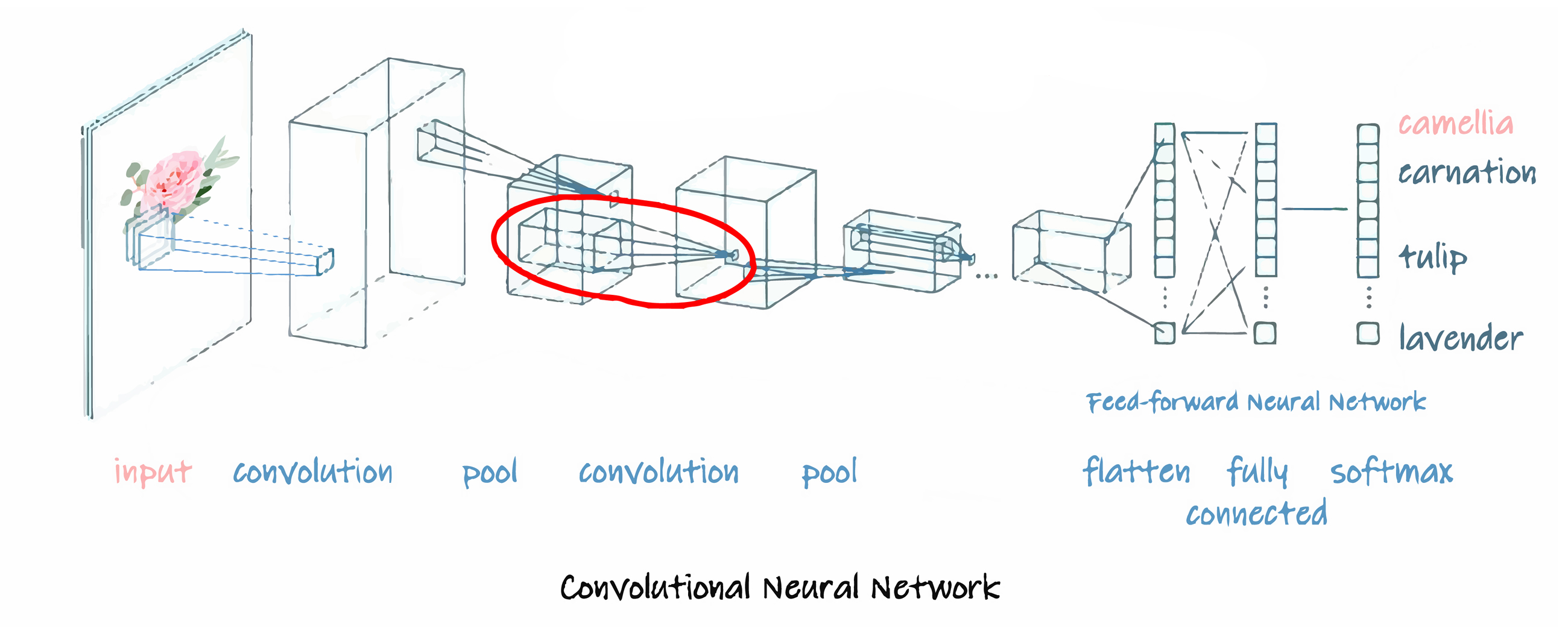
在自然语言处理中,卷积神经元网络的运算如下:
(1)对每一句话中的单词采用向量进行表示,因此每一句话就是一个2维矩阵,并对这句话进行卷积运算,本质是对每句话的子集,即一个或多个单词分别进行卷积( convolution )计算,在卷积计算中,过滤器的运动幅度( stride )也是可变参数。
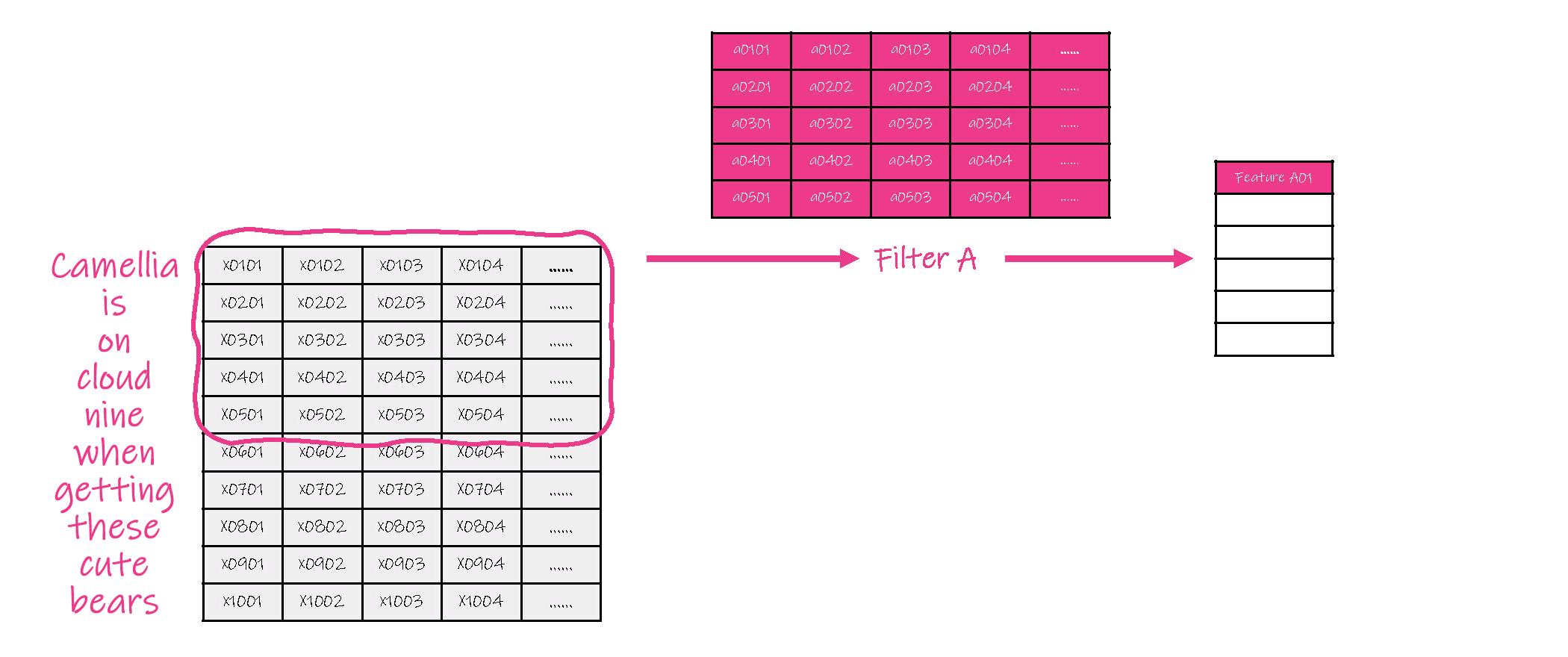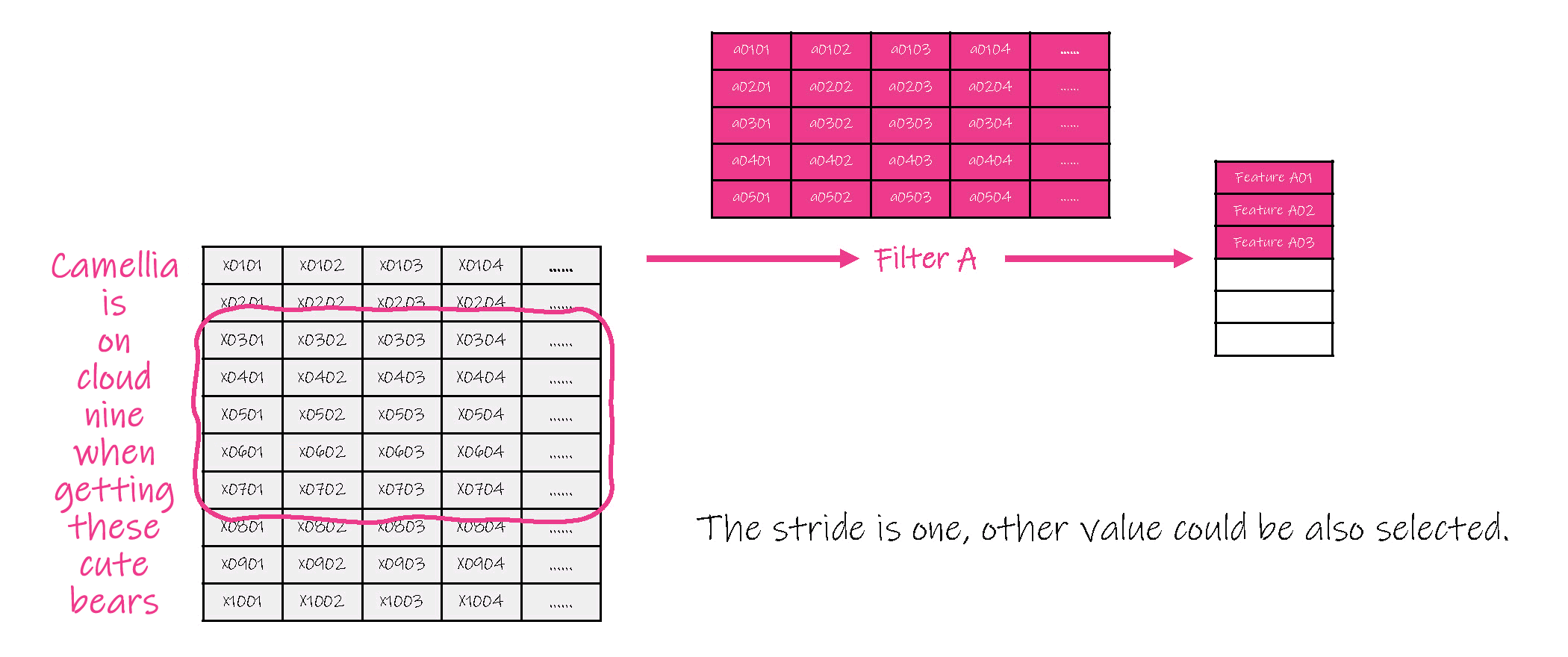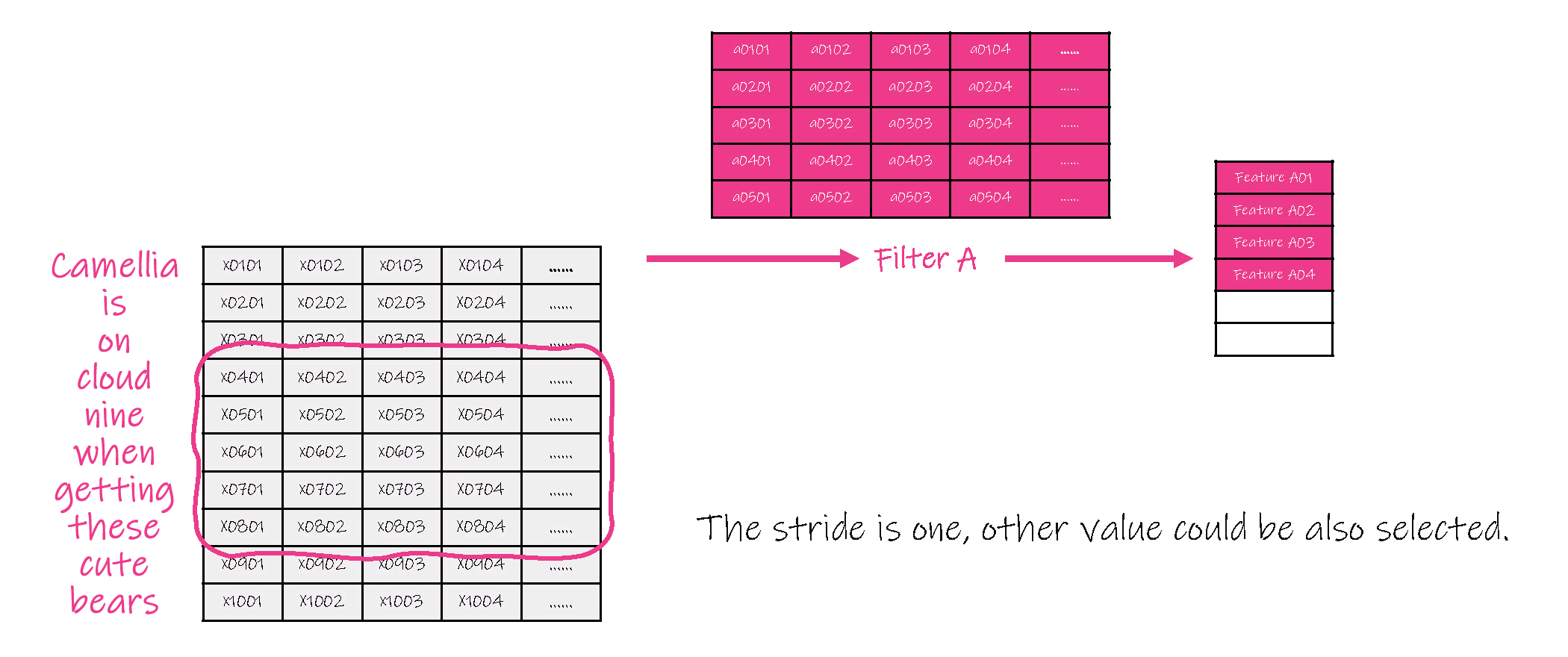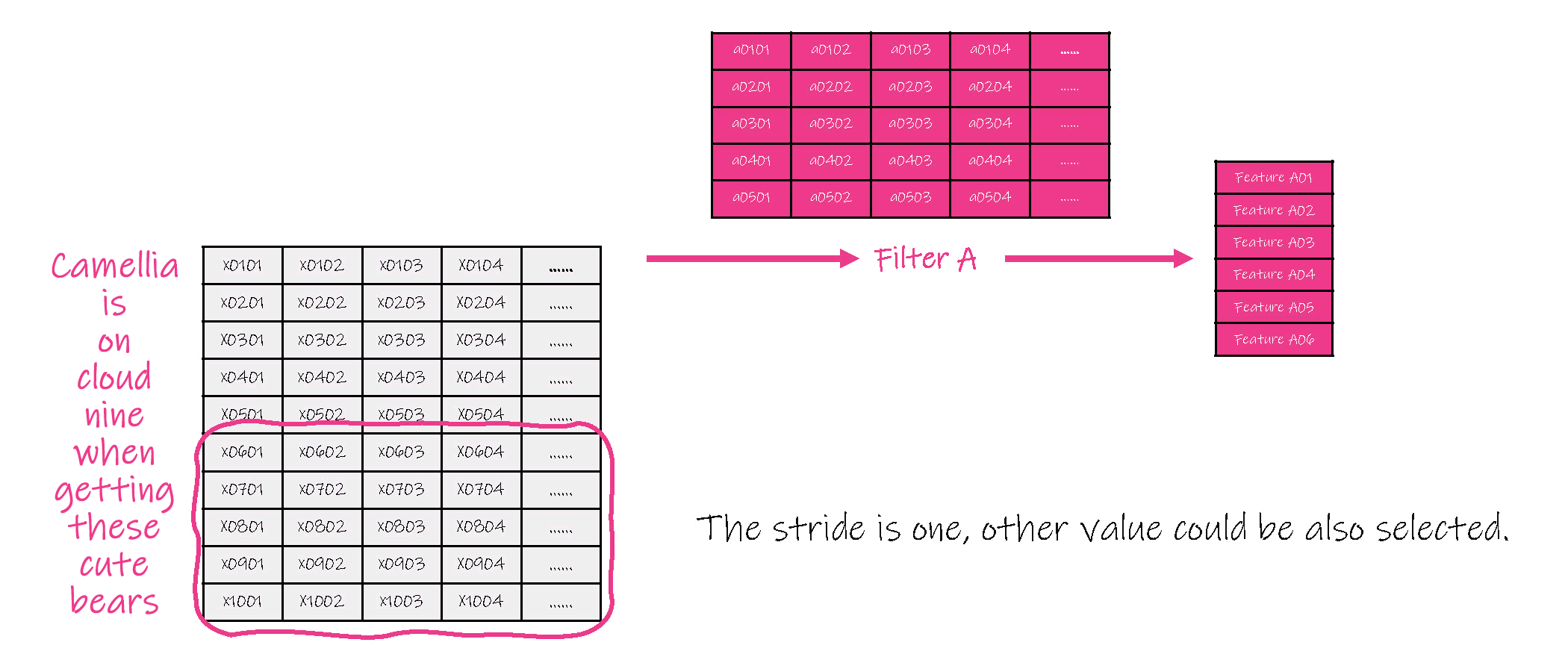
(2)对卷积结果进行联合( pool ),即选取各子集卷积结果中的一个值作为的代表值。
(3)之后再次进行卷积,再次联合。
……
(4)需要注意的是,在步骤(1)到(3)的卷积运算中,选用的过滤器,可以不止一个,即对同一子集,还可以选用不同的过滤器,分别进行运算,得出多个卷积运算结果,因此卷积的结果是一个立方体。
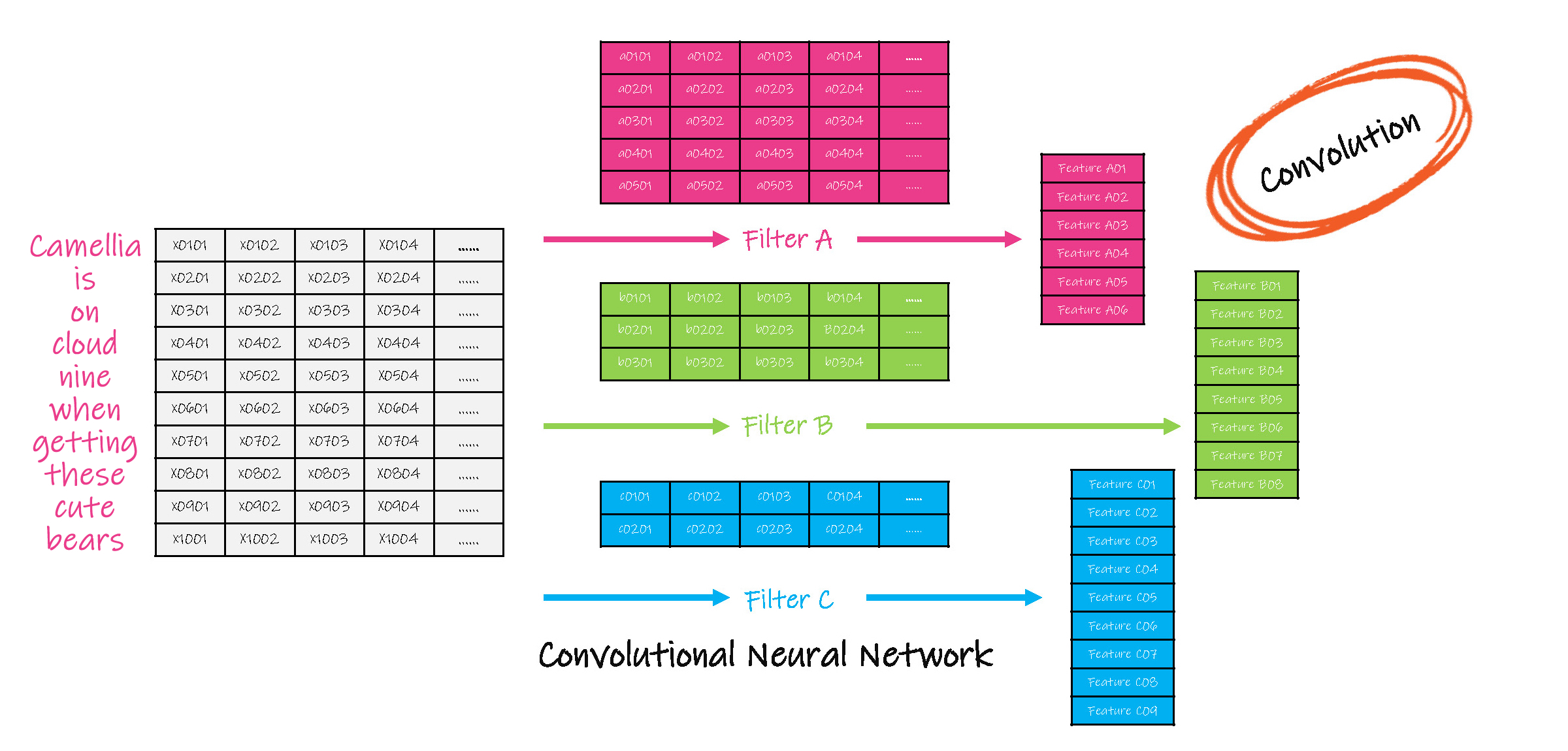
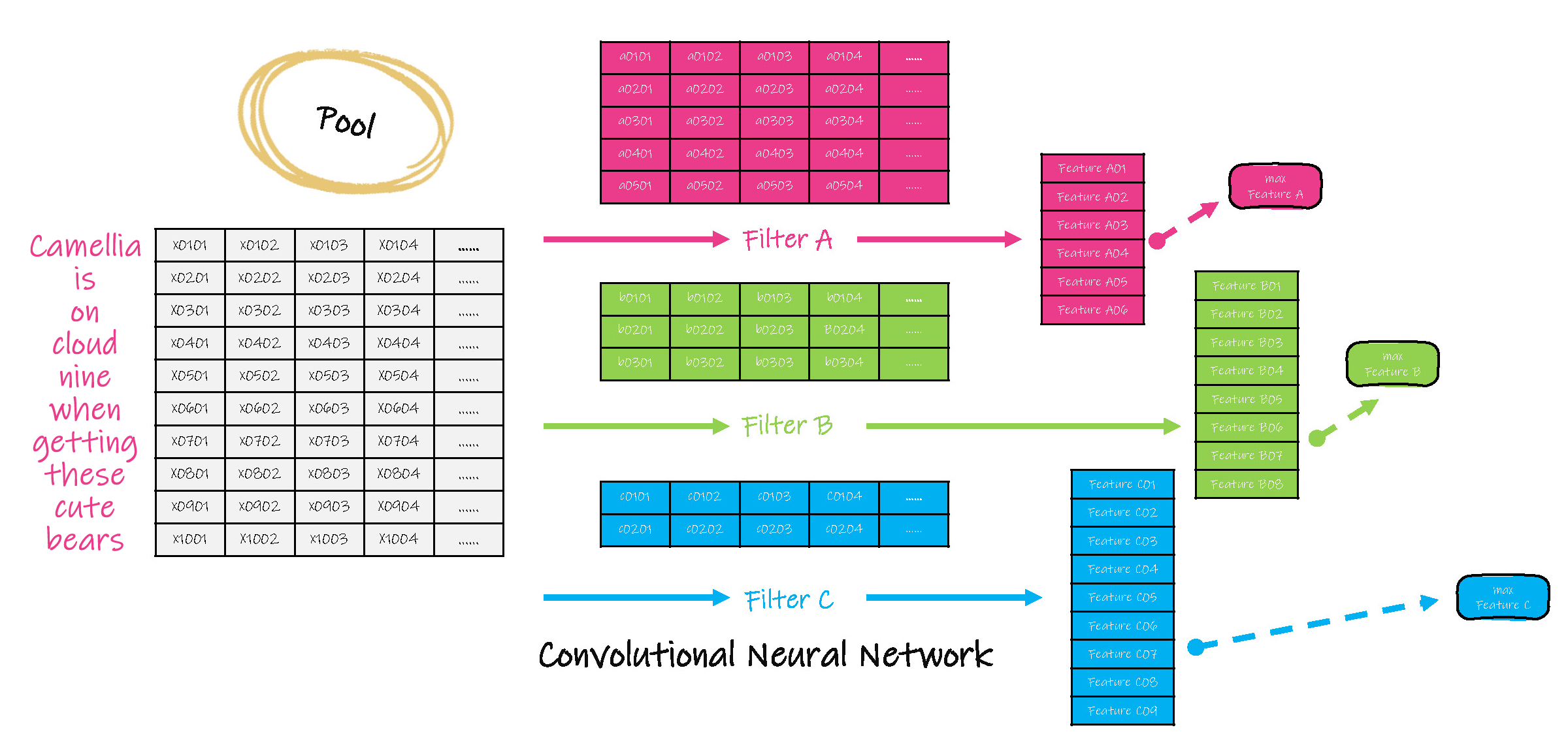
(5)基于多个过滤器,最终的联合输出也有多个值,此时将这多个值同时作为一个前向神经元网络的输入,即扁平化( flatten )。
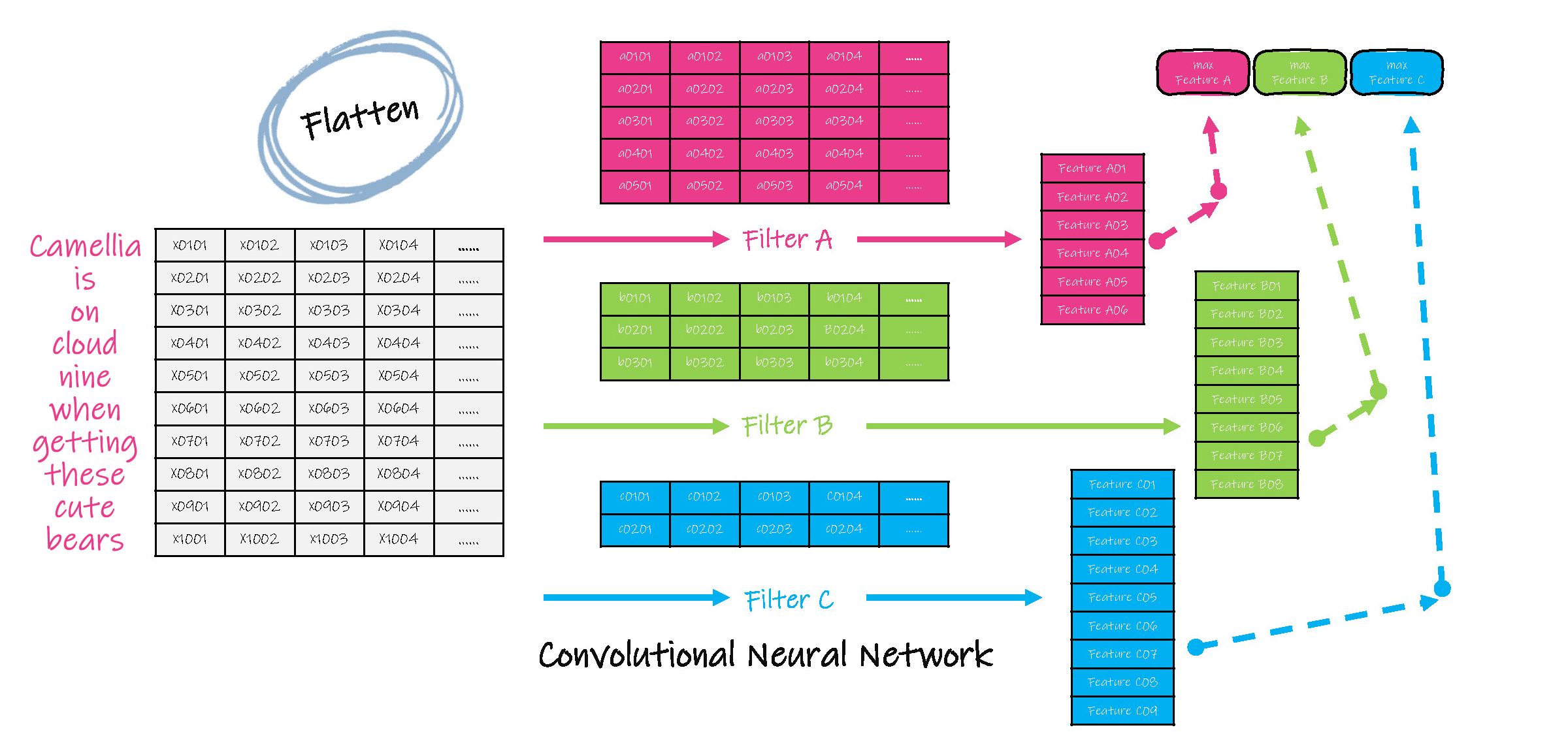
(6)在此前向神经元网络中完成后续计算,并得到最终的输出。
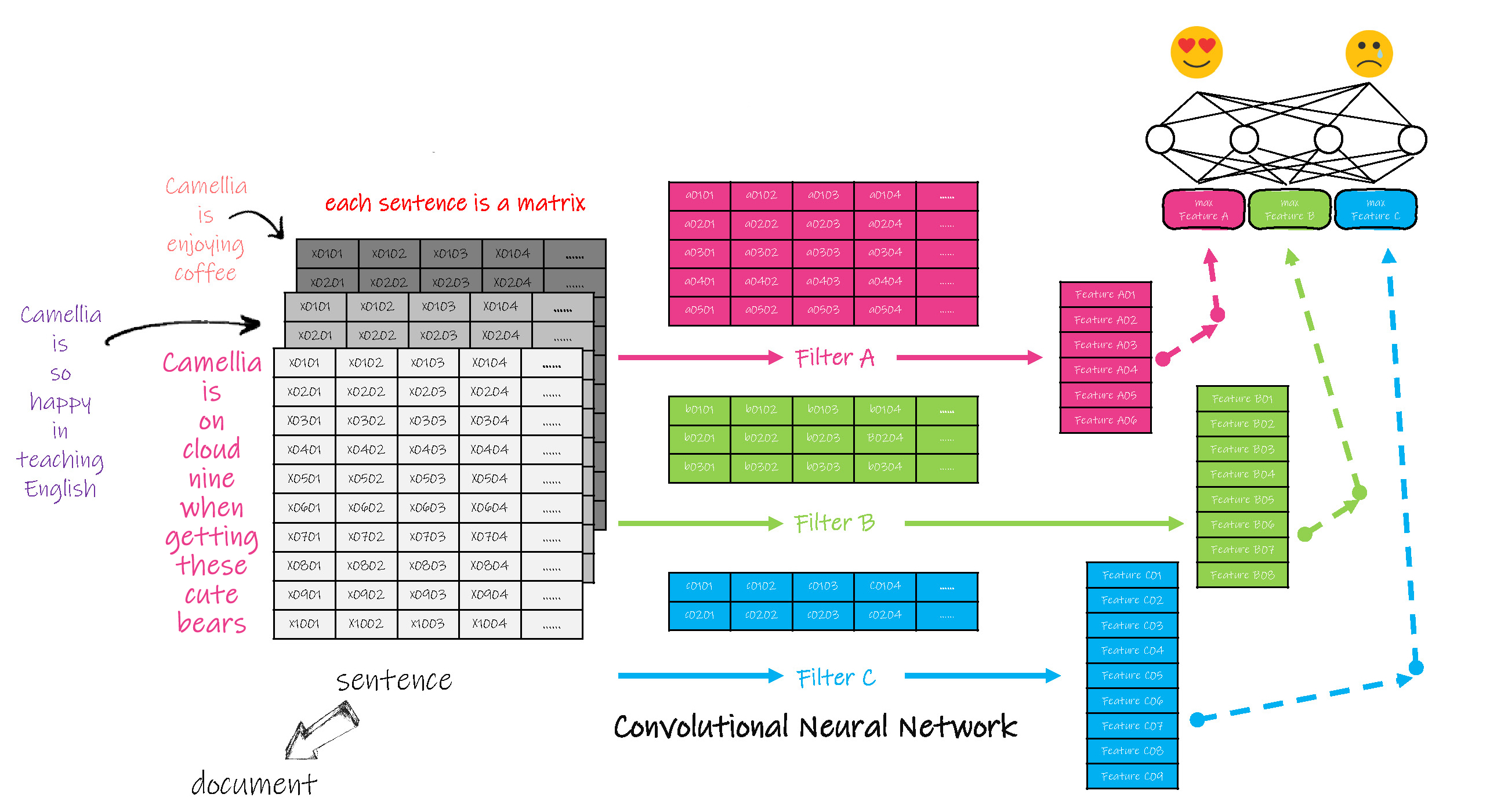
当需要分析一篇文章时,可以对每句话同时按照上述步骤进行计算,把计算过程中的立方体升级为多维空间体。
卷积神经元网络自身的特点使其在情感分析和文本主题分类等任务中,效果强大。
卷积神经元网络的建模过程同样可以采取监督、半监督和非监督学习等方式,而需要学习的参数包括:子集大小,过滤器大小、过滤器参数、过滤器运动幅度,联合方式,以及前向神经元网络中的权值等。

卷积神经元网络既然能够很好地处理图像,分析文本。在语音识别中也可以发挥强大的作用。可以把声波按照不同的时间长度分割为不同的子集,每段声波中的频率不同,往往是多个声源产生的声波的叠加结果,对这些频率进行卷积运算,分析每种声源的边界频率,并根据不同时间段的综合,最终提取到每个单词的发音,并转化为对应的单词,完成语音识别。
采用神经元网络建立自然语言模型并基于深度学习进行自然语言处理的方法还有很多,各种技术也正在蓬勃发展, Camellia Café 在这里仅是通过两种典型网络介绍人工智能设备语言技术的开发思路和使用方法,更多的知识和技术有待读者朋友去拓展阅读。
深度学习和语法规则的结合
无论是普通的机器学习,还是基于复杂人工神经元网络的深度学习,其本质都是根据样本建立黑箱模型,而基于语言学知识建立的模型或语言库属于白箱模型。实际中黑箱模型仅基于样本数据,虽然减轻了人工建模的复杂程度,但是样本的好坏影响到模型的鲁棒性。白箱模型基于规则,准确可靠,但是规则的输入耗时耗力。
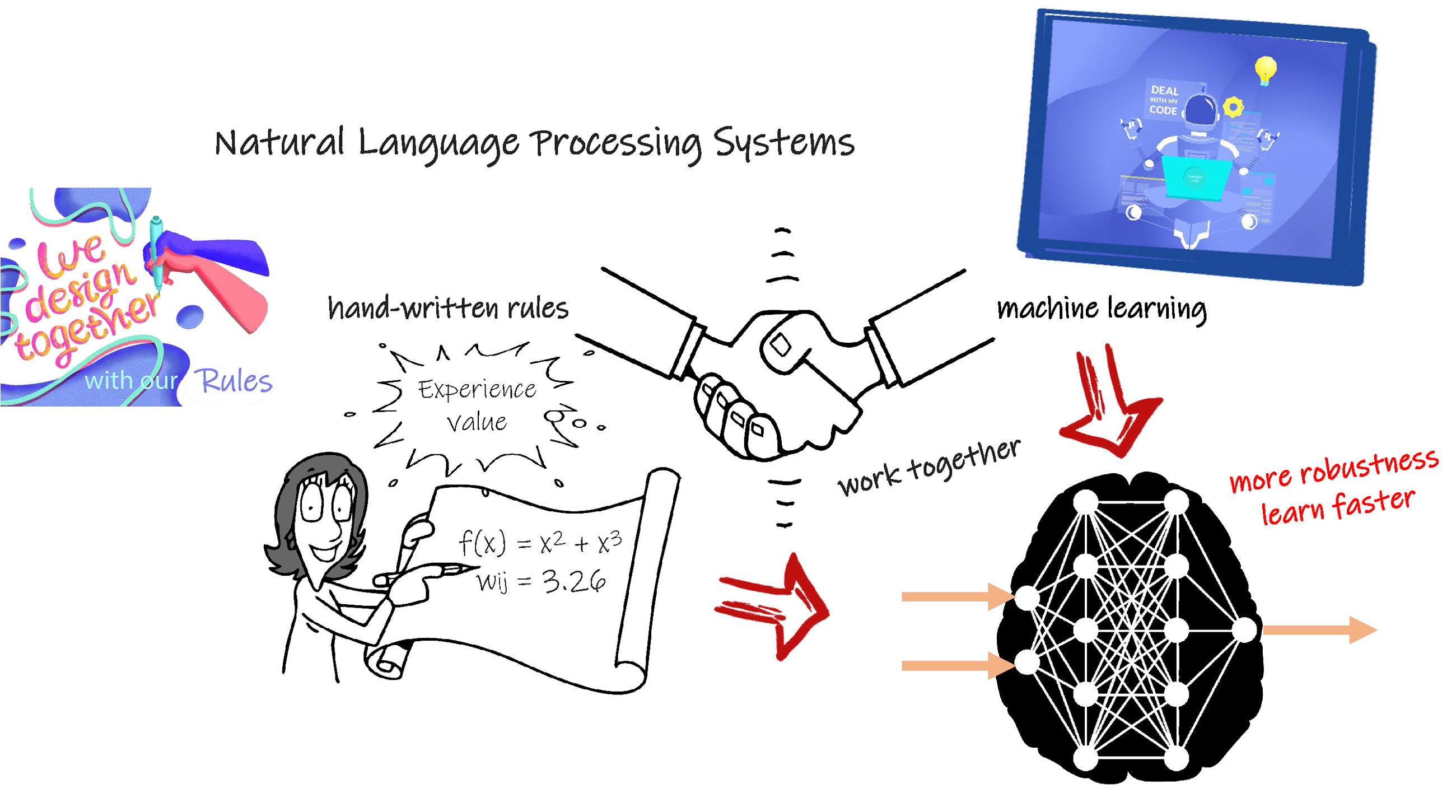
人工智能设备可以充分结合这两大技术,即使在黑箱模型的学习过程中,也可以融入规则,加快学习速度。采用黑箱和白箱相结合的灰箱模型功能一定会更加强大,因为灰箱继承了人类的先验知识,也发挥了人工智能设备的高速性能。
实现上述人工智能设备的语言智能的载体就是硬件技术。概要地说,需要:
CPU 、 GPU 和 TPU 等处理芯片,实现算法运算,完成模型的学习和建立。
采用大规模存储器和云端存储技术,结合数据库技术,实现超大规模数据的存储,高效保存收集到的模型学习样本,并建立规则库。
采用麦克风等采集声音、采用高清晰照相机和摄像机等采集图像及视频,采用立体声音响和耳机等播放语音…… 这实现了语言数据的采集和产生。智能手机等终端设备以及物联网设备的普及更是极大地便利了这些功能。
Wi-Fi、蓝牙、5G等无线通讯技术,更加提速和便利了数据的传输。
芯片
CPU ( Central Processing Unit )和 GPU ( Graphics Processing Unit )对我们都不陌生,我们通常认为 GPU 在图像处理上有广泛的应用,为什么要在人工智能设备的语言处理上也广泛采用 GPU 呢?首先看看 CPU 和 GPU 的不同:
CPU 追求的是低延迟( Low-latency ), GPU 追求的是高计算能力( High throughput )。
CPU 擅长处理串行指令, GPU 更胜于并行指令的执行。
GPU 比 CPU 有更多的内核( core )处理器。
CPU 需要大量的存储单元, GPU 需要的存储单元较少。
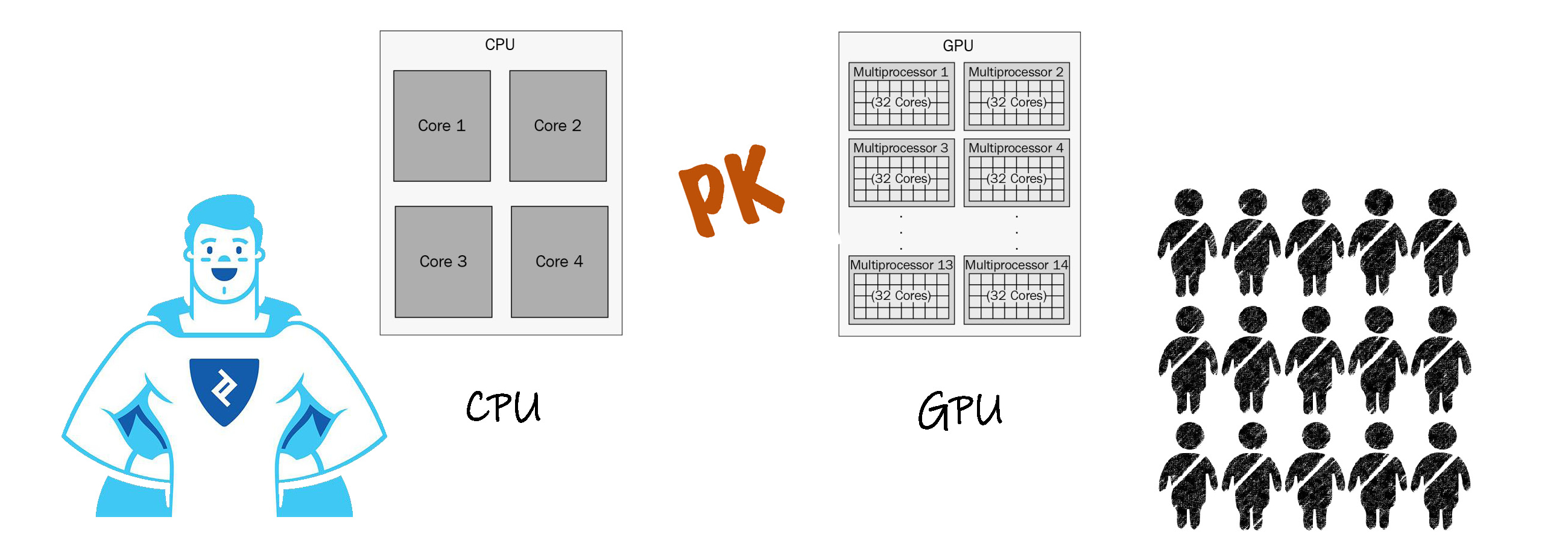
做个简单的比喻, CPU 就好比一个超人,而 GPU 就好似一个普通工程师的团队,但是集体的力量往往不能忽视。上述基于复杂人工神经元网络的深度学习技术,由于通常含有多个输入和输出,要求有较高的并行计算能力,而此时 GPU 的优势就相对强一些。
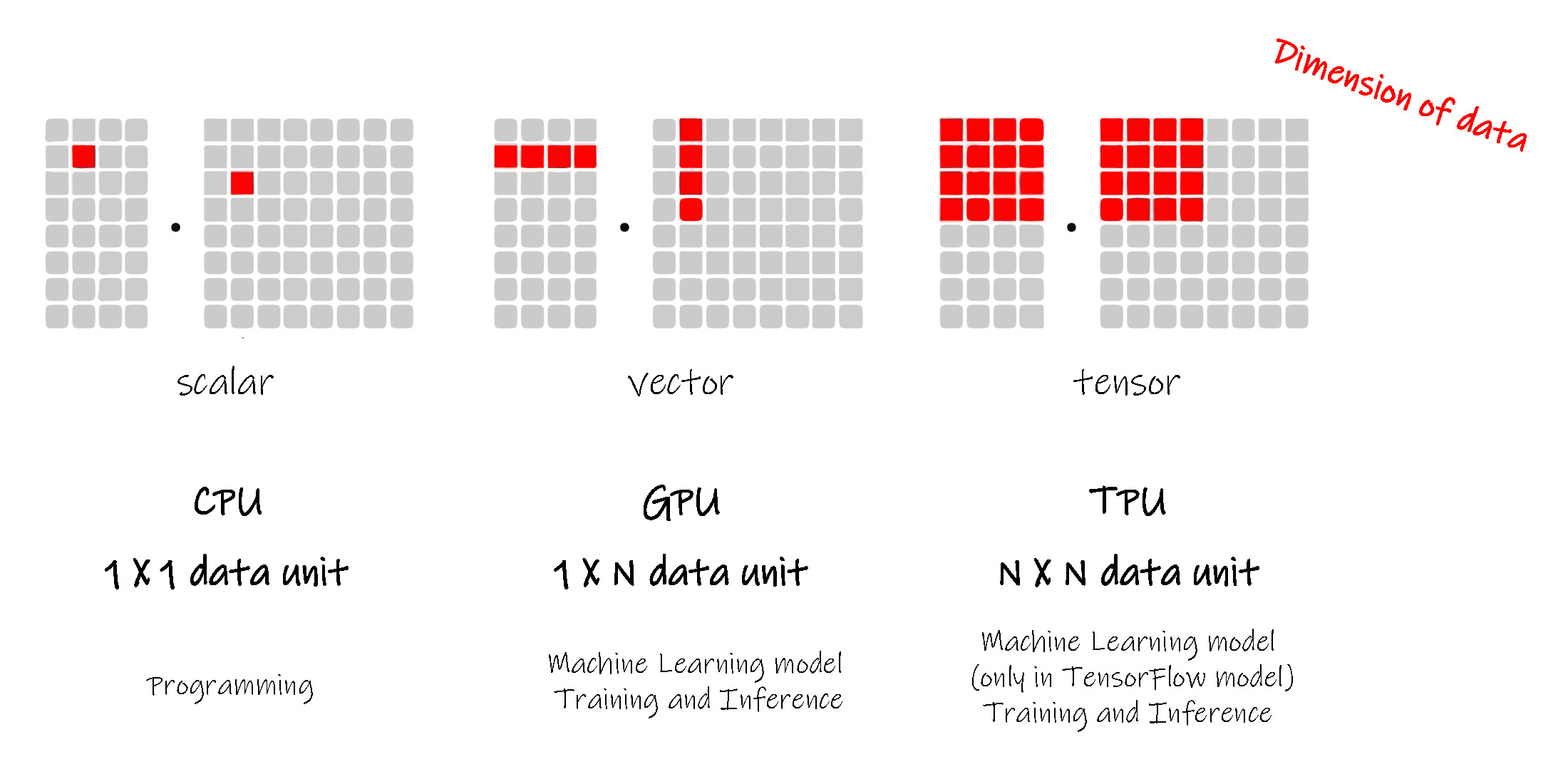
TPU ( Tensor Processing Unit ) 则是在 GPU 的技术上进一步降低单个内核的能力,更多地增多内核的数量,使并行处理的能力更高,更容易处理高维向量和计算高维矩阵。
无线通讯
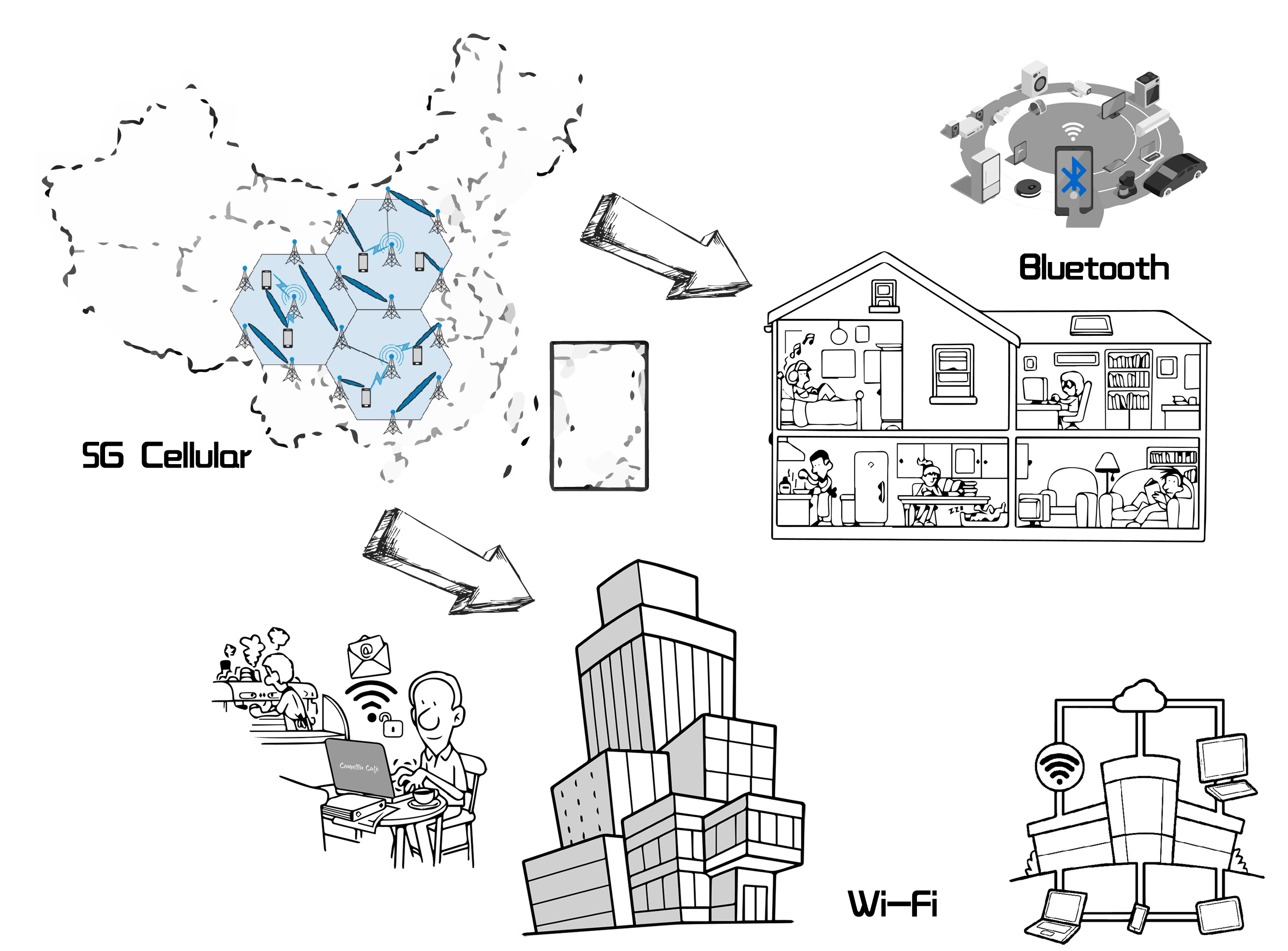
同样是无线通讯,5G 这个第5代移动蜂窝通讯技术涉及的范围是整个国家或全球,其工作频率为24~86GHz,通常国家或政府会管理该工作频率,各个运营商需要得到授权,才能开发、建设本公司在该频段工作的基站。相对于 4G 第4代移动蜂窝通讯技术,5G 由于频率的提高,信号的波长会变短,信号的穿透能力相对降低,因此需要建立更多的基站。
Wi-Fi 工作的范围仅限于一个房间、办公室或办公大楼,其工作频率为2GHz或5GHz ,这些频率不需要授权,通过无线路由器既可以建立无线局域网。
蓝牙( Bluetooth )也是一种无线通讯模式,其主要用于各种智能设备的互联,工作范围大概限制在一个房间内,工作频率在2.45GHz。
量子计算

当前摩尔定律( Moore's Law)已经达到了瓶颈,这意味着传统计算机性能的提高受到了极大地限制,制约计算机芯片进一步微型化的一个重要原因是散热问题。近些年来,量子力学( Quantum Mechanics )的快速发展,为量子计算机的开发带来了希望。 量子计算机将从本质概念上改变我们的思维,其超高性能将为人工智能设备的发展推波助澜。
上述人工智能的语言智能技术还是一种弱的人工智能技术,本质上还是局限在语言方面,即使在语言智能方面,当前的技术还是局限于认知,没有实现真正的思考。如何真正意义上使人工智能设备像人类一样具有高度的语言智能呢? Camellia Café 在前一期内容中讲述了培养孩子时,语言智能可以助力其他智能的发展,其他多元智能也可以拓展语言智能的发展。按照这个思路,在人工智能设备中,把其他智能技术的某些方面综合到语言智能技术中,用其他智能技术获取的数据信息及其对应功能帮助人工智能设备的听、说、读、写,一定会大大提高机器人、自动导航汽车等的语言智能技术。其实强人工智能的实质不就是使人工智能设备如同我们人类一样,成为各种多元智能高度发达的综合体吗?
我们不再称呼人工智能设备为它们,而是称作他们/她们。

逻辑智能( Logic/Mathematical )助力语言智能
如果您已经阅读了本文的全部,您一定会感到数学的伟大。的确,无论是算法还是模型,都离不开数学,或许此时此刻,您有些后悔没有在大学学好数学。充分建立人工智能设备的逻辑智能,对其语言智能的提高将不言而喻。
音乐智能( Music/Musical )助力语言智能
进一步把语音学( Phonetics )和音韵学( Phonology )的知识运用到人工智能设备中,让其可以聆听人类的音乐演出,跟着节奏做出反应;使其可以根据文字去谱曲、去演奏;学习音乐家的灵感,其谱写的歌词往往更优雅内涵。
空间智能( Picture/Spatial )助力语言智能
光学字符识别技术( Optical Character Recognition Technology ) 的发展将便利在图像、视频中提取文字信息,更加准确的实现不同字体、不同风格的手写文字的信息提出。人工智能设备不仅可以欣赏书法,还可以创造自己的流派。
动觉智能( Body/Bodily-Kinesthetic )助力语言智能
演讲的同时,充分发挥肢体语言,展现不同的语境( context )。
自然智能( Nature/Naturalist )助力语言智能
识别气候、地理、天文,了解动物、植物…… 发挥语用学( Pragmatics )的知识,通过周围的自然环境表达不同的语义。
人际智能( People/Interpersonal)助力语言智能
同样发挥语用学( Pragmatics )的知识,建立有效的人与机器、机器与机器的沟通方式,演讲者和聆听者需要不时地互换角色,获取对方的反馈信息。反馈将有助于人工智能设备的学习及其内部模型的完善。
内省智能( Self/Intrapersonal )助力语言智能
人工智能设备同样需要时刻深入了解自己,反思自己,提高自己,这也是一种非监督的学习过程。
存在智能( Life/Existential )助力语言智能
人工智能设备也有自己的生命,在不停地发展成长,他们需要思考自己的成长,思考自己存在的价值。毫无疑问,优良的人工智能设备不仅有利于人类的生活和工作,更有利于整个世界的发展进步。如果人工智能设备自己能够意识到这些,那么他们/她们将更加勤奋地追求进步。
道德智能( Moral )助力语言智能
让人工智能设备也读些寓言,理解名言警句吧,让他们/她们也能够明白其中的含义,他们/她们需要终生恪尽职守,兢兢业业。有待一日他们/她们在某些方面强于我们时,更重要的是他们/她们要追寻高尚的道德和崇高的理想。
先来看个结果矛盾的实验:
如果让一个人拿着笔和纸,手动模拟一个计算机芯片的运算,其结果是0.01 MIPS,即每秒1万条指令。
如果让一台超级计算机模拟人类大脑的一个神经元细胞,其结果是人类具有50,000,000,000 MIPS的性能,即每秒5万万亿条指令。

英国数学家、逻辑学家,被称为计算机科学之父,人工智能之父的 Alan Mathison Turing :
如果我们与一台机器对话交流时,我们不能辨别出对方的身份是机器,那么称这台机器具有智能。
待到那时,我们的孩子和人工智能设备交往时,我们觉得它们都变成了他们/她们,而他们/她们就不觉得它们是它们了,而都是咱们了,这就是图灵测试的最终结果。